Các bước thiết kế Data Warehouse (Kho dữ liệu) tiêu chuẩn bao gồm 7 giai đoạn cốt lõi: (1) Thu thập và xác định yêu cầu nghiệp vụ; (2) Thiết kế kiến trúc tổng thể; (3) Lựa chọn phương pháp mô hình hóa dữ liệu (Kimball hoặc Inmon); (4) Thiết kế mô hình dữ liệu chi tiết (Bảng Fact và Dimension); (5) Xây dựng đường ống dữ liệu ETL/ELT; (6) Triển khai lưu trữ và nạp dữ liệu lịch sử; (7) Tối ưu hóa hiệu năng và thiết lập bảo mật hệ thống.
Trong kỷ nguyên quản trị dựa trên số liệu, dữ liệu được ví như nguồn nhiên liệu thô của mọi doanh nghiệp. Tuy nhiên, nếu nguồn nhiên liệu này nằm rải rác ở nhiều hệ thống quản trị khác nhau như CRM, ERP, các phần mềm bán hàng hay hệ thống lưu trữ log website, doanh nghiệp sẽ không thể có được một bức tranh toàn cảnh.
Việc chạy các báo cáo phân tích tổng hợp trực tiếp trên các cơ sở dữ liệu vận hành (OLTP) thường xuyên gây ra tình trạng nghẽn mạng, thậm chí là treo hệ thống phần mềm cốt lõi. Đây là lý do vì sao các doanh nghiệp bắt buộc phải xây dựng một Data Warehouse độc lập. Đây là một công việc đặc thù của Kỹ sư dữ liệu Data Engineer.
Bài viết này sẽ hướng dẫn chi tiết các bước thiết kế Data Warehouse xây dựng kho dữ liệu theo quy trình chuẩn công nghiệp, giúp hệ thống của bạn vận hành tối ưu, có tính toàn vẹn cao và sẵn sàng mở rộng quy mô.
Mục Lục
- Phân biệt hai phương pháp luận thiết kế Data Warehouse kinh điển
- 1. Phương pháp Tiếp cận Từ dưới lên - Bottom-Up
- 2. Phương pháp Tiếp cận Từ trên xuống - Top-Down (Bill Inmon)
- Chi tiết 7 bước thiết kế Data Warehouse xây dựng kho dữ liệu toàn diện
- Bước 1: Thu thập và xác định yêu cầu nghiệp vụ (Business Requirements Gathering)
- Bước 2: Thiết kế kiến trúc tổng thể (Architecture Design)
- Bước 3: Lựa chọn mô hình hóa dữ liệu (Data Modeling)
- Bước 4: Thiết kế chi tiết bảng Fact và bảng Dimension
- Bước 5: Xây dựng đường ống dữ liệu ETL/ELT (Data Integration)
- Bước 6: Triển khai lưu trữ và nạp dữ liệu lịch sử (Data Loading & Deployment)
- Bước 7: Tối ưu hóa hiệu năng, bảo mật và bảo trì
- Những sai lầm kinh điển cần tránh khi thiết kế Data Warehouse
- Các câu hỏi thường gặp về quy trình thiết kế Data Warehouse (Q&A)
- 1. Sự khác biệt lớn nhất giữa Star Schema và Snowflake Schema là gì? Nên chọn loại nào?
- 2. Tại sao hiện nay các doanh nghiệp có xu hướng chuyển từ kiến trúc ETL sang ELT?
- 3. Những công cụ hàng đầu nào được khuyên dùng để xây dựng đường ống dữ liệu?
- Kết luận
Phân biệt hai phương pháp luận thiết kế Data Warehouse kinh điển
Trước khi bắt tay vào cấu trúc các bảng số liệu, nhà kiến trúc dữ liệu (Data Architect) cần phải lựa chọn một phương pháp luận cốt lõi để định hình tư duy thiết kế. Lịch sử ngành dữ liệu ghi nhận hai trường phái kinh điển tương phản nhau:
1. Phương pháp Tiếp cận Từ dưới lên - Bottom-Up
Phương pháp của Ralph Kimball đặt nhu cầu thực tế của các phòng ban kinh doanh lên hàng đầu. Theo đó, bạn sẽ tiến hành xây dựng các Data Mart (Kho dữ liệu thu nhỏ, phục vụ riêng cho một phòng ban như Phòng Sales, Phòng Marketing, Phòng Nhân sự) trước. Sau khi các Data Mart này vận hành ổn định, chúng sẽ được tích hợp và liên kết lại với nhau để tạo thành một Data Warehouse tổng thể cho toàn doanh nghiệp.
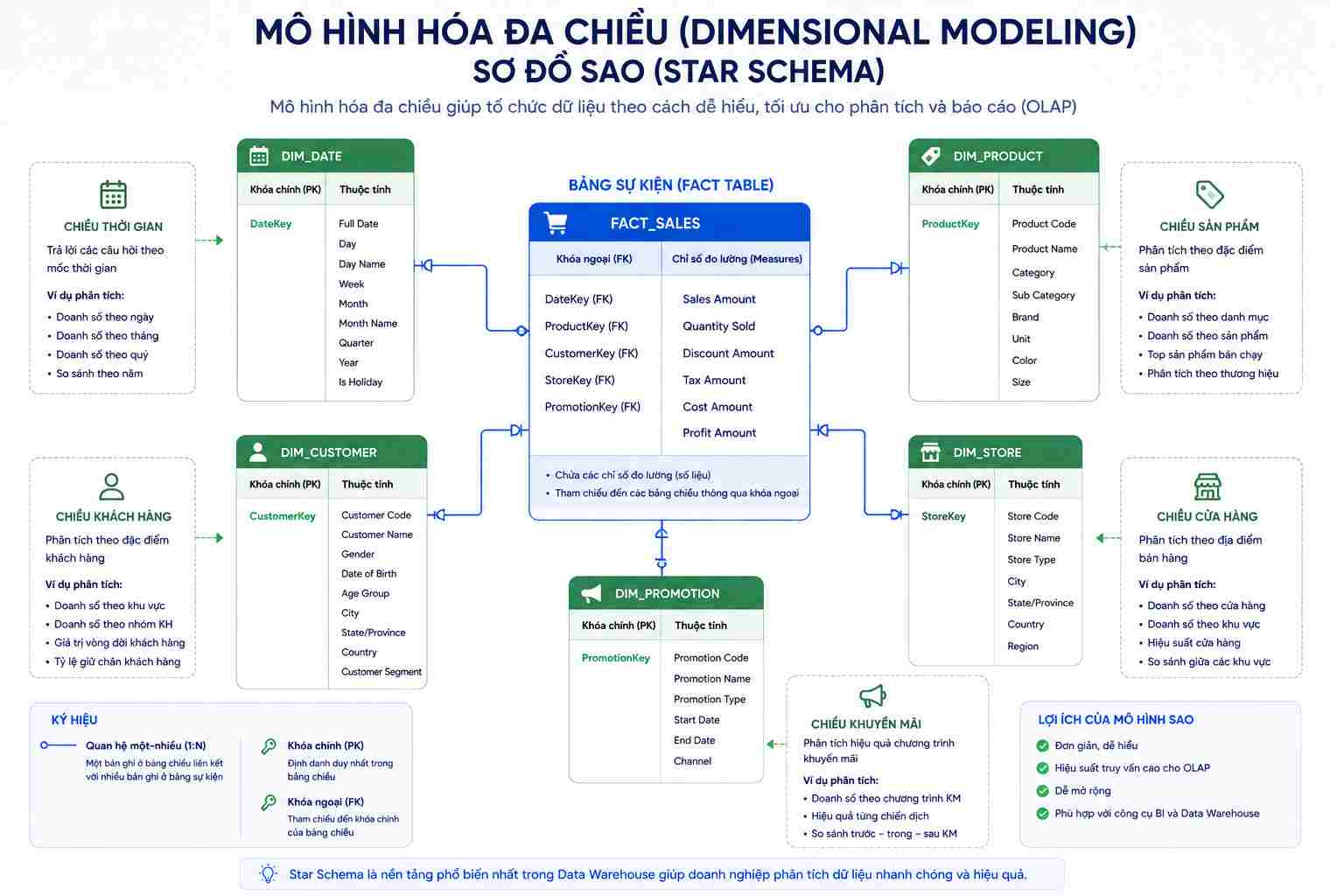
Trường phái này sử dụng kỹ thuật mô hình hóa đa chiều (Dimensional Modeling) với cấu trúc sơ đồ sao (Star Schema).
Ưu điểm: Triển khai nhanh chóng, sớm đem lại giá trị sử dụng thực tế cho doanh nghiệp, chi phí đầu tư ban đầu thấp.
Nhược điểm: Nếu không có sự kiểm soát chặt chẽ về mặt định nghĩa dữ liệu giữa các phòng ban ngay từ đầu, hệ thống rất dễ bị phân mảnh và khó đồng bộ về sau.
2. Phương pháp Tiếp cận Từ trên xuống - Top-Down (Bill Inmon)
Trái ngược hoàn toàn với Kimball, Bill Inmon định nghĩa Data Warehouse phải là một kho lưu trữ dữ liệu tập trung, hợp nhất toàn bộ dữ liệu của doanh nghiệp ngay từ bước đầu tiên. Dữ liệu nạp vào kho tổng này phải được chuẩn hóa nghiêm ngặt về dạng chuẩn 3 (3NF - Third Normal Form) để triệt tiêu hoàn toàn sự trùng lặp. Từ kho tổng đồ sộ này, các cấu trúc Data Mart nhỏ mới được trích xuất ra để phục vụ nhu cầu phân tích của từng bộ phận riêng biệt.
Ưu điểm: Dữ liệu có tính nhất quán cực kỳ cao, kiểm soát chặt chẽ tính toàn vẹn và không bị trùng lặp thông tin.
Nhược điểm: Thời gian triển khai rất dài (có thể mất nhiều năm), chi phí cực kỳ lớn và đòi hỏi sự phối hợp tuyệt đối của toàn bộ tập đoàn.
Lời khuyên thực chiến: Ngày nay, tuyệt đại đa số các doanh nghiệp công nghệ và doanh nghiệp vừa và lớn đều ưu tiên lựa chọn phương pháp Bottom-Up của Kimball hoặc áp dụng mô hình lai (Hybrid) để tối ưu hóa thời gian sinh lời của dữ liệu.
Chi tiết 7 bước thiết kế Data Warehouse xây dựng kho dữ liệu toàn diện
Để xây dựng một hệ thống kho dữ liệu bền vững, đội ngũ kỹ sư dữ liệu cần tuân thủ nghiêm ngặt theo quy trình 7 bước tiêu chuẩn dưới đây:
Bước 1: Thu thập và xác định yêu cầu nghiệp vụ (Business Requirements Gathering)
Sai lầm lớn nhất của các kỹ sư công nghệ là lao vào viết code và cấu trúc database khi chưa hiểu rõ doanh nghiệp cần gì. Bước đầu tiên và quan trọng nhất là phải ngồi lại với các bên liên quan như Business Users, Ban giám đốc, Trưởng phòng ban… để xác định:
Doanh nghiệp cần theo dõi những chỉ số cốt lõi (KPIs) nào? Ví dụ: Doanh thu thuần, tỷ lệ giữ chân khách hàng, biên lợi nhuận gộp theo từng dòng sản phẩm.
Họ cần chiều phân tích dữ liệu như thế nào? Ví dụ: Xem doanh thu theo thời gian ngày/tháng/năm, theo khu vực địa lý, hoặc theo nhóm độ tuổi khách hàng.
Xác định rõ bản đồ nguồn dữ liệu đầu vào hiện tại: Dữ liệu đang nằm ở những nguồn nào? Định dạng dữ liệu là gì (SQL Server, MySQL, các file Excel tĩnh, hay các dữ liệu phi cấu trúc như Log từ ứng dụng mobile)?
Bước 2: Thiết kế kiến trúc tổng thể (Architecture Design)
Sau khi có yêu cầu nghiệp vụ, bạn cần định hình kiến trúc hạ tầng cho kho dữ liệu. Một kiến trúc Data Warehouse tiêu chuẩn thường gồm 3 tầng (Three-tier Architecture):
Staging Area (Vùng đệm trung gian): Nơi tiếp nhận và lưu trữ tạm thời dữ liệu thô được trích xuất từ các hệ thống nguồn trước khi đưa vào xử lý. Tầng này giúp giảm tải cho hệ thống vận hành chính.
Data Warehouse chính thức: Nơi lưu trữ toàn bộ dữ liệu đã được làm sạch, đồng bộ và tổ chức theo mô hình đa chiều dài hạn.
Data Marts (Tầng phân phối): Các kho dữ liệu thành phần đã được phân tách cấu trúc, sẵn sàng kết nối với các công cụ báo cáo trực quan như Power BI, Tableau để người dùng khai thác.
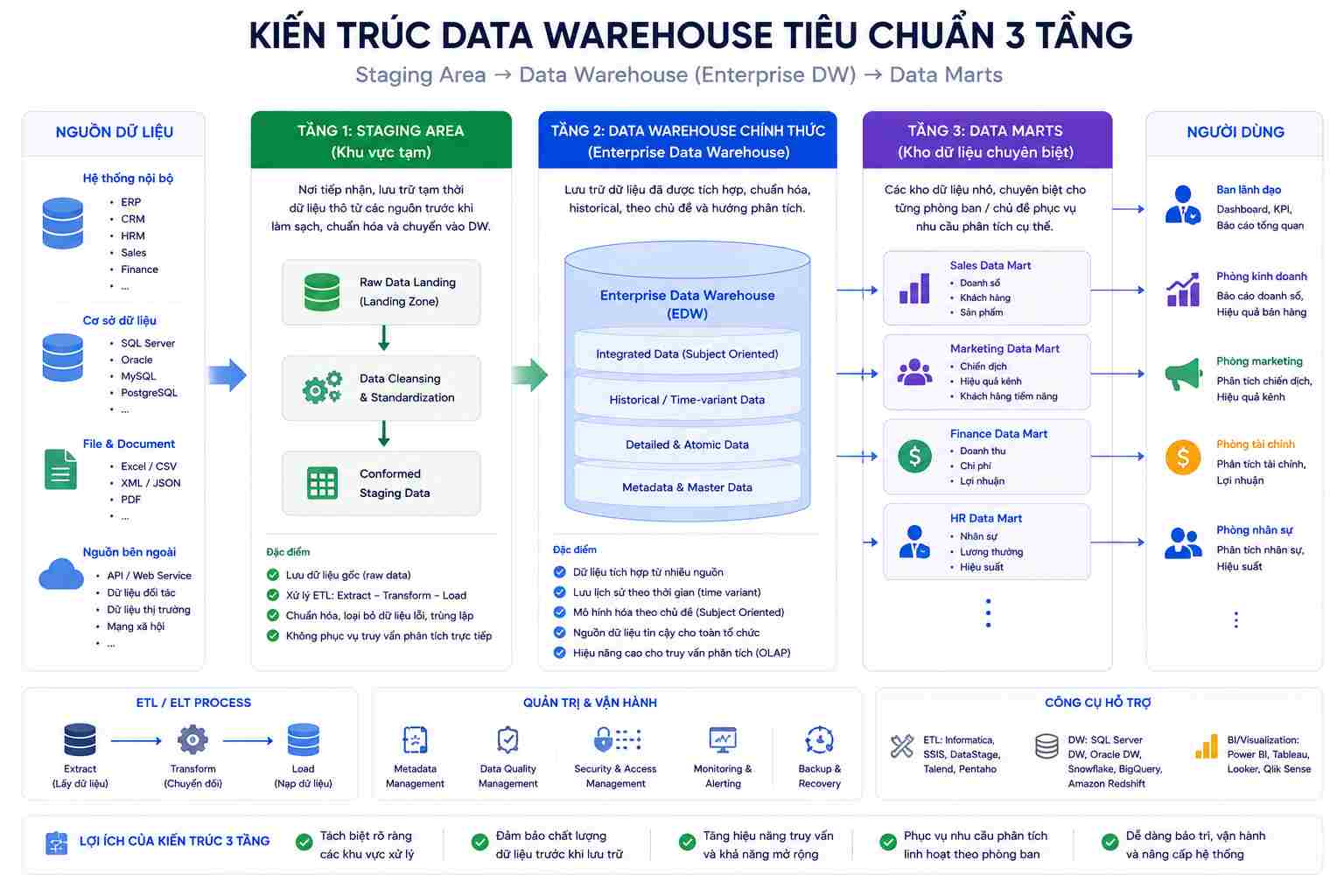
Ở bước này, bạn cũng phải đưa ra quyết định về hạ tầng: Triển khai trên máy chủ vật lý của công ty hay sử dụng Cloud Data Warehouse như Google BigQuery, Snowflake, AWS Redshift... Hạ tầng Cloud đang là xu hướng áp đảo nhờ khả năng tự động mở rộng dung lượng và chi phí vận hành linh hoạt.
Bước 3: Lựa chọn mô hình hóa dữ liệu (Data Modeling)
Mô hình hóa dữ liệu là việc bạn vẽ ra cấu trúc liên kết logical giữa các thực thể dữ liệu trong kho. Đối với Data Warehouse, hai mô hình thiết kế phổ biến nhất bao gồm:
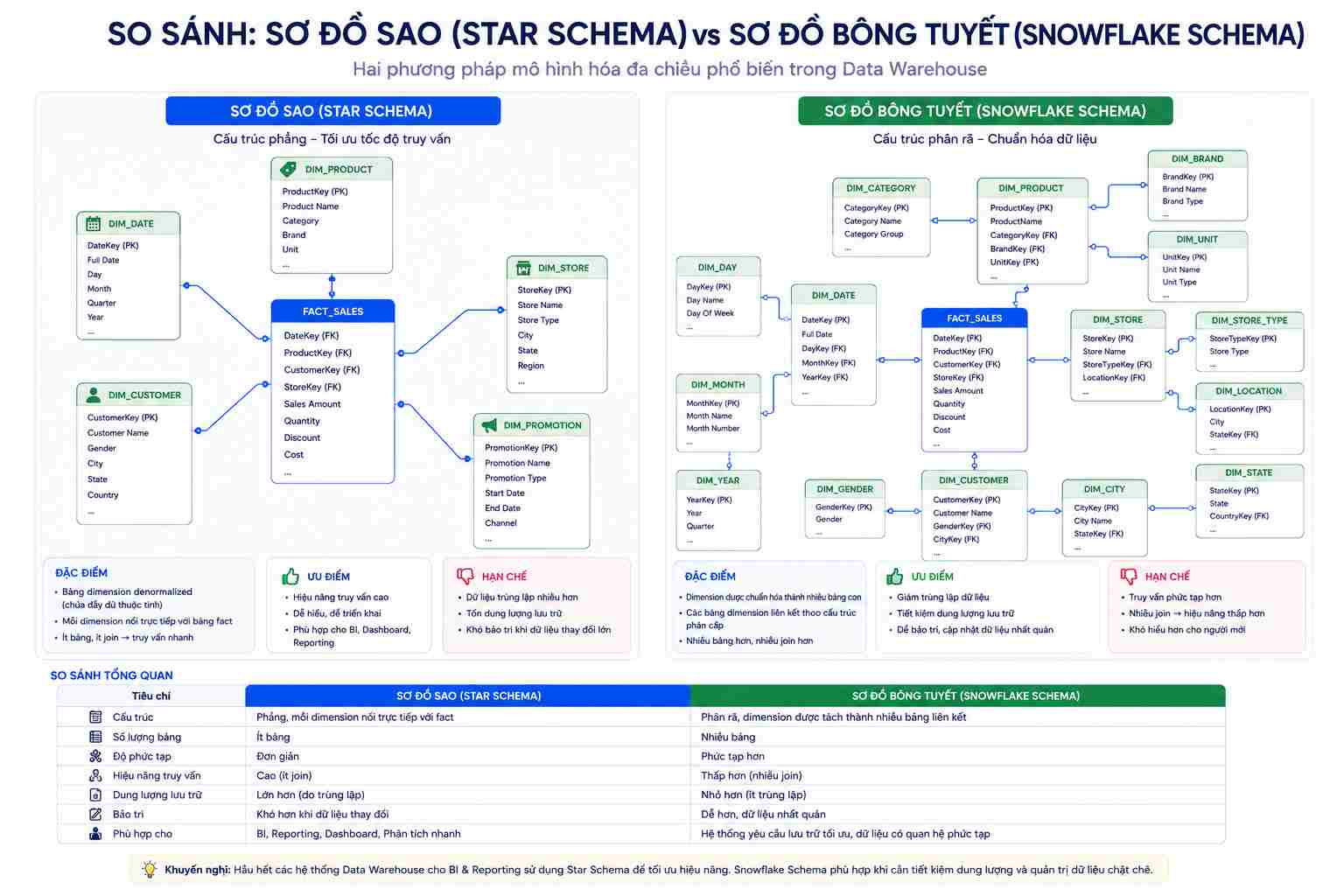
Star Schema (Sơ đồ sao): Gồm một bảng dữ liệu trung tâm lớn kết nối trực tiếp với các bảng mô tả xung quanh. Cấu trúc này không được chuẩn hóa tối đa (Denormalized), giúp giảm thiểu các lệnh liên kết bảng phức tạp, từ đó tối ưu hóa tốc độ truy vấn ở mức cực nhanh.
Snowflake Schema (Sơ đồ bông tuyết): Là dạng mở rộng của sơ đồ sao, trong đó các bảng mô tả xung quanh tiếp tục được phân rã và chuẩn hóa (Normalized) thành các bảng nhỏ hơn nữa. Mô hình này giúp tiết kiệm dung lượng lưu trữ nhưng làm chậm tốc độ truy vấn do máy tính phải thực hiện nhiều lệnh JOIN dữ liệu cùng lúc.
Bước 4: Thiết kế chi tiết bảng Fact và bảng Dimension
Đây là bước bạn trực tiếp định nghĩa cấu trúc vật lý của các bảng dữ liệu trong sơ đồ đã chọn ở Bước 3. Bạn cần phân tách rõ ràng hai loại bảng:
Bảng Fact (Bảng sự kiện): Nằm ở tâm sơ đồ, lưu trữ các số liệu đo lường định lượng của một sự kiện kinh doanh đã xảy ra. Ví dụ, trong bảng Fact Bán Hàng, các cột dữ liệu sẽ là: Số lượng sản phẩm bán ra, Đơn giá, Thành tiền, Chiết khấu. Bảng Fact thường chứa hàng triệu cho đến hàng tỷ dòng dữ liệu và liên tục tăng trưởng theo thời gian.
Bảng Dimension (Bảng chiều/mô tả): Bao bọc xung quanh bảng Fact, lưu trữ các thông tin thuộc tính nền tảng để giải thích cho các con số trong bảng Fact. Ví dụ: Bảng Dimension Khách Hàng (chứa Tên, Giới tính, Địa chỉ), bảng Dimension Sản Phẩm (chứa Tên danh mục, Thương hiệu, Màu sắc).
Trong quá trình này, kỹ sư hệ thống phải thiết lập các Surrogate Key hay còn gọi là khóa thay thế dưới dạng số nguyên tăng tự động để làm khóa chính cho các bảng Dimension, thay vì dùng trực tiếp khóa chính của hệ thống nguồn là Natural Key. Điều này giúp bảo vệ kho dữ liệu khỏi những thay đổi cấu trúc đột ngột từ hệ thống nguồn bên ngoài.
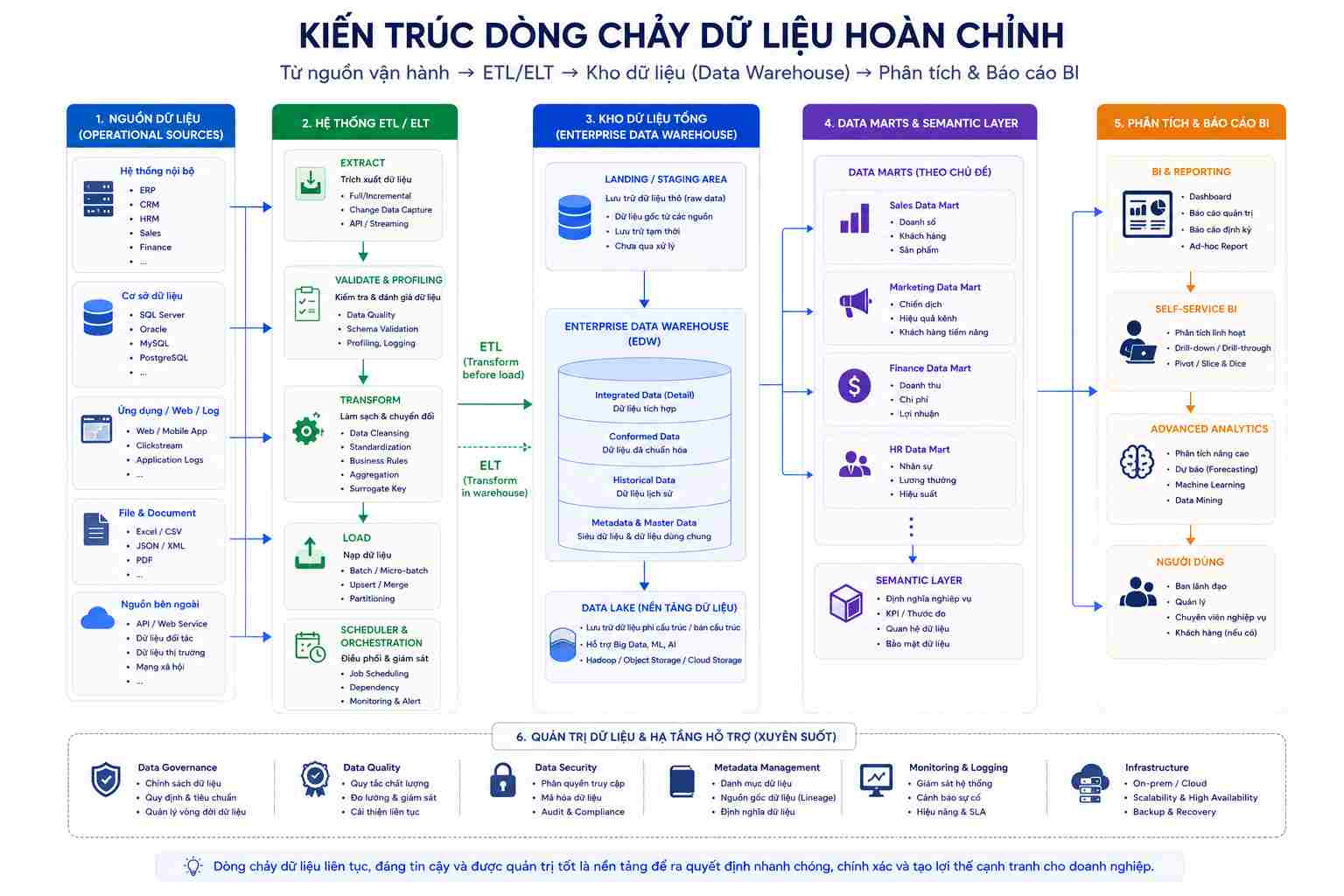
Bước 5: Xây dựng đường ống dữ liệu ETL/ELT (Data Integration)
Đường ống dữ liệu (Data Pipeline) cực kỳ quan trọng giúp vận chuyển dữ liệu liên tục vào kho. Bạn cần lựa chọn giữa hai cơ chế:
ETL (Extract - Transform - Load): Dữ liệu được trích xuất từ nguồn (Extract), đưa vào vùng đệm trung gian để làm sạch, biến đổi, định dạng lại (Transform) rồi mới nạp vào kho dữ liệu chính thức (Load). Phương pháp này phù hợp với hạ tầng máy chủ On-premise truyền thống.
ELT (Extract - Load - Transform): Dữ liệu thô được trích xuất và nạp thẳng vào kho dữ liệu lớn trước (Load), sau đó mới tận dụng năng lực tính toán cực mạnh của các nền tảng đám mây để thực hiện biến đổi dữ liệu (Transform). Đây là kiến trúc chuẩn của các hệ thống Modern Data Stack hiện nay.
Trong khâu này, bạn phải viết mã nguồn hoặc cấu hình các công cụ để xử lý các vấn đề: Loại bỏ dữ liệu rác, đồng bộ hóa định dạng ngày tháng, mã hóa thông tin nhạy cảm và thiết lập lịch trình (Scheduling) tự động chạy đường ống vào các khung giờ thấp điểm (ví dụ: 2 giờ sáng hằng ngày).
Bước 6: Triển khai lưu trữ và nạp dữ liệu lịch sử (Data Loading & Deployment)
Trước khi đưa hệ thống vào vận hành chính thức, bạn cần tiến hành hai giai đoạn nạp dữ liệu:
Nạp dữ liệu lịch sử (Historical Data Migration): Di chuyển toàn bộ dữ liệu tích lũy của doanh nghiệp từ nhiều năm trước vào kho dữ liệu mới. Quá trình này đòi hỏi kiểm thử nghiêm ngặt vì khối lượng dữ liệu khổng lồ dễ gây ra lỗi tràn bộ nhớ hoặc sai lệch cấu trúc.
Cấu hình nạp dữ liệu gia tăng (Incremental Load): Thiết lập cơ chế để hằng ngày, hệ thống chỉ trích xuất và nạp thêm những bản ghi mới phát sinh hoặc có sự thay đổi (sử dụng kỹ thuật CDC - Change Data Capture), tránh việc phải nạp lại toàn bộ kho dữ liệu từ đầu gây lãng phí tài nguyên.
Bước 7: Tối ưu hóa hiệu năng, bảo mật và bảo trì
Một kho dữ liệu thiết kế đúng chuẩn phải đảm bảo thời gian trả kết quả truy vấn cho người dùng chỉ tính bằng giây. Để đạt được điều đó, kỹ sư dữ liệu cần thực hiện tối ưu hóa:
Phân vùng dữ liệu (Partitioning): Chia nhỏ các bảng Fact khổng lồ thành các vùng lưu trữ độc lập theo thời gian (ví dụ: Phân vùng theo tháng hoặc theo năm). Khi người dùng chạy báo cáo tháng 5/2026, hệ thống chỉ quét đúng vùng dữ liệu đó chứ không quét toàn bộ kho dữ liệu của 10 năm.
Thiết lập chính sách bảo mật (Data Governance): Mã hóa dữ liệu lưu trữ (Encryption at rest), phân quyền truy cập nghiêm ngặt đến từng cấp độ dòng và cột dữ liệu (Row-level & Column-level security). Đảm bảo nhân viên phòng Sales chỉ nhìn thấy dữ liệu doanh thu của phòng mình, không xem được dữ liệu lương của phòng nhân sự.
Những sai lầm kinh điển cần tránh khi thiết kế Data Warehouse
Trong thực tế triển khai dự án, rất nhiều doanh nghiệp phải "đập đi xây lại" hệ thống kho dữ liệu do mắc phải các sai lầm cốt lõi sau:
Thiết kế thuần kỹ thuật, xa rời bài toán nghiệp vụ: Hệ thống được xây dựng rất hoành tráng về mặt công nghệ, nhưng các chỉ số xuất ra lại không đúng với nhu cầu cần phân tích của phòng kinh doanh, dẫn đến việc kho dữ liệu bị bỏ hoang không ai sử dụng.
Bỏ qua bước làm sạch dữ liệu ở Staging Area: Nguyên lý bất biến của ngành dữ liệu là "Garbage in, Garbage out" (Rác nạp vào thì rác đầu ra). Nếu khâu làm sạch dữ liệu ở Bước 5 bị làm sơ sài, kho dữ liệu sẽ chứa các số liệu sai lệch, dẫn đến việc ban lãnh đạo đưa ra các quyết định chiến lược sai lầm.
Không tính toán đến khả năng mở rộng (Scalability): Thiết kế cấu trúc bảng quá cứng nhắc khiến hệ thống hoạt động tốt với dung lượng vài Gigabyte ban đầu, nhưng lập tức bị nghẽn và quá tải khi quy mô dữ liệu tăng lên mức Terabyte sau vài năm doanh nghiệp tăng trưởng.
Các câu hỏi thường gặp về quy trình thiết kế Data Warehouse (Q&A)
1. Sự khác biệt lớn nhất giữa Star Schema và Snowflake Schema là gì? Nên chọn loại nào?
Sự khác biệt cốt lõi nằm ở mức độ chuẩn hóa dữ liệu của các bảng Dimension. Star Schema giữ cấu trúc phẳng (không chuẩn hóa), chấp nhận trùng lặp dữ liệu trong bảng Dimension để đổi lấy tốc độ truy vấn cực nhanh do không phải JOIN nhiều bảng. Snowflake Schema phân rã các bảng Dimension thành nhiều tầng nhỏ (chuẩn hóa 3NF) để tiết kiệm dung lượng bộ nhớ lưu trữ, nhưng bù lại cấu trúc truy vấn phức tạp và chậm hơn.
Đối với các hệ thống Data Warehouse hiện đại, Star Schema luôn là sự lựa chọn ưu tiên vì chi phí mua thêm dung lượng lưu trữ ngày nay rất rẻ, trong khi tốc độ trải nghiệm báo cáo của người dùng mới là yếu tố quyết định.
2. Tại sao hiện nay các doanh nghiệp có xu hướng chuyển từ kiến trúc ETL sang ELT?
Kiến trúc ETL truyền thống được hình thành khi năng lực phần cứng của máy chủ lưu trữ còn hạn chế và đắt đỏ, do đó người ta phải biến đổi dữ liệu thật gọn gàng ở vùng đệm rồi mới nạp vào kho. Hiện nay, với sự ra đời của các Cloud Data Warehouse (như Google BigQuery, Snowflake), sức mạnh tính toán và lưu trữ đã trở nên vô hạn với chi phí thấp. Kiến trúc ELT cho phép nạp dữ liệu thô cực nhanh vào kho mà không gặp nút thắt cổ chai ở khâu biến đổi, sau đó mới dùng chính sức mạnh xử lý song song của đám mây để biến đổi dữ liệu, giúp tăng tốc độ vận hành của toàn bộ hệ thống lên gấp nhiều lần.
3. Những công cụ hàng đầu nào được khuyên dùng để xây dựng đường ống dữ liệu?
Tùy thuộc vào quy mô tài chính và đội ngũ kỹ thuật, doanh nghiệp có thể lựa chọn các nhóm công cụ sau:
Nhóm công cụ Mã nguồn mở (Open-source): Apache Airflow, Prefect (Dùng cho việc lập lịch và quản trị luồng công việc phức tạp).
Nhóm công cụ Hiện đại (Modern Data Stack): dbt (data build tool) - Công cụ hàng đầu hiện nay chuyên phục vụ cho khâu "Transform" dữ liệu bằng ngôn ngữ SQL quen thuộc; Fivetran hoặc Airbyte chuyên cho khâu trích xuất và nạp dữ liệu tự động.
Nhóm giải pháp Đám mây tích hợp sẵn: AWS Glue, Azure Data Factory, Google Cloud Dataflow.
Tìm hiểu thêm:
- Khóa học Data Engineer - Thực chiến thiết kế Data Werahouse chuyên nghiệp
Kết luận
Xây dựng một kho dữ liệu không phải là một dự án phần mềm ngắn hạn mà là một hành trình kiến trúc dài hạn phục vụ cho sự phát triển bền vững của doanh nghiệp. Việc thấu hiểu và áp dụng chính xác các bước thiết kế Data Warehouse xây dựng kho dữ liệu từ khâu lắng nghe yêu cầu nghiệp vụ, mô hình hóa cấu trúc Fact/Dim chuẩn xác cho đến việc tối ưu hóa đường ống ELT sẽ giúp doanh nghiệp sở hữu một "bộ não số" minh bạch, sắc bén, trực tiếp chuyển hóa các con số khô khan thành lợi thế cạnh tranh vượt trội trên thị trường.




