Khóa Học AI Engineer 2026 – Xây LLM, RAG, Agent Thực Chiến


Thời lượng
62 buổi

Hình thức đào tạo
Online qua Zoom

Học phí
Liên hệ
Tổng quan
Mức lương hấp dẫn:
AI Engineer vững kiến thức và kỹ năng được dự đoán là một trong những vị trí săn đón hàng đầu trên toàn cầu. Theo các báo cáo công nghệ, nhu cầu tuyển dụng nhân sự liên quan đến khoá học AI trí tuệ nhân tạo tăng trưởng vượt bậc trên 40% mỗi năm, đặc biệt tại các thị trường sôi động như Mỹ, Singapore và Việt Nam.Thách thức nhân lực:
Nhu cầu tuyển dụng AI Engineer tăng trưởng mạnh trong khi nguồn nhân lực được đào tạo bài bản vẫn còn khan hiếm. Đây là lý do vì sao khóa học trí tuệ nhân tạo chuyên sâu ngày càng trở thành lựa chọn chiến lược cho những ai muốn thăng tiến nhanh. Xem chia sẻ từ những người đã chuyển ngành thành công.Khóa học AI Engineer — Toàn diện từ nền tảng đến thực chiến:
Chương trình học AI online linh hoạt với lộ trình học bài bản, bắt đầu từ nền tảng Machine Learning và Data Science, tiến dần đến các kỹ năng AI chuyên sâu. Dù bạn mới bắt đầu học lập trình AI cơ bản hay muốn nâng cấp lên khóa học lập trình AI nâng cao, chương trình này đều đáp ứng được. Với hình thức khóa học trí tuệ nhân tạo online, bạn học mọi lúc, mọi nơi, không bị giới hạn bởi địa lý.Chương trình đặc biệt phù hợp cho những ai đang tìm kiếm:
- Khóa học AI engineer và khóa học kỹ sư AI chuẩn quốc tế, học ngay tại Việt Nam.- Khóa học lập trình AI từ cơ bản đến nâng cao, có áp dụng thực tế ngay sau khi học.
- Khoá học AI trí tuệ nhân tạo toàn diện, khóa học AI online linh hoạt từ bất cứ đâu.
- Khóa học về trí tuệ nhân tạo phù hợp cả người mới lẫn người đã có nền tảng công nghệ.
Điểm khác biệt của AI Engineer Fullstack 2026:
- Lộ trình toàn diện: Bao quát từ Python core, Machine Learning, Deep Learning đến Reinforcement Learning (RL) và Explainable AI (XAI) — bạn không bỏ sót bất kỳ mảng nào quan trọng.- Cập nhật GenAI & Agent: Đi sâu vào Transformer, Fine-tuning LLMs và xây dựng hệ thống Agentic AI workflow — những kỹ năng đang được săn đón nhất trên thị trường.
- Tư duy AI có trách nhiệm: Đào tạo Responsible AI (Bias & Fairness), giúp bạn xây dựng các mô hình không chỉ mạnh mà còn minh bạch và công bằng.
- Thực chiến 100%: Tham gia Mentor-Guided Projects mô phỏng quy trình làm việc thực tế tại doanh nghiệp — bạn tốt nghiệp với portfolio thực sự, không chỉ kiến thức lý thuyết. Khám phá thêm các khóa học liên quan như Big Data & Data Engineer để xây dựng hệ sinh thái kỹ năng toàn diện.

Lợi ích khóa học
Đào tạo trực tuyến
Các buổi học sẽ diễn ra qua các nền tảng trực tuyến như Zoom, Microsoft Teams. Học viên tham gia các buổi học trực tiếp với giảng viên qua hình thức online.
Nội dung buổi học
Sẽ bao gồm trung bình 60% lý thuyết và 40% thực hành. Các bài thực hành được lấy từ các bài toán thực tế, giúp học viên áp dụng ngay kiến thức vào công việc.
Tài liệu học tập
Video record, Slide bài giảng, hướng dẫn thực hành chi tiết.
Video bài giảng
Học viên có thể xem lại video các buổi học để ôn tập và nắm vững kiến thức.
Tương tác trực tiếp
Học viên có thể trao đổi trực tiếp 1-1 với giảng viên hoặc trợ giảng để được giải đáp thắc mắc và hỗ trợ trong quá trình học.
Lợi ích chỉ có tại COLE
- CAM KẾT THỰC TẬP TỐI THIỂU 2 THÁNG
- CAM KẾT KẾT NỐI GIỚI THIỆU VIỆC LÀM
Mục tiêu học tập
Nắm vững tư duy Khoa học dữ liệu, thành thạo công cụ nghiên cứu tiêu chuẩn (Jupyter Notebook, Google Colab) để thiết lập và quản lý môi trường phát triển dự án AI.
Làm chủ ngôn ngữ Python từ cơ bản đến nâng cao; khai thác tối đa sức mạnh của bộ thư viện kinh điển (NumPy, Pandas, Matplotlib, Seaborn) để thao tác, cấu trúc và trực quan hóa các tập dữ liệu phức tạp.
Khai phá bản chất dữ liệu bằng phương pháp thống kê mô tả, kiểm định giả thuyết và kỹ thuật EDA chuyên sâu, tạo tiền đề tối ưu cho việc lựa chọn và huấn luyện mô hình học máy.
Hiểu sâu kiến trúc toán học và tự tay triển khai các thuật toán kinh điển (Hồi quy, Phân lớp, Phân cụm như Linear Regression, Decision Tree, SVM, K-Means) trên thư viện Scikit-Learn.
Thành thạo kỹ thuật xử lý văn bản nền tảng (TF-IDF, Word Embedding), ứng dụng thuật toán Collaborative Filtering và luật kết hợp để xây dựng hệ thống gợi ý cá nhân hóa cho doanh nghiệp.
Nắm trọn cơ chế vận hành của mạng Neural nhân tạo, lan truyền ngược (Backpropagation) và các kỹ thuật tối ưu hóa thuật toán; ứng dụng xử lý các bài toán hình ảnh và văn bản phức tạp.
Làm chủ vòng đời dự án AI từ bước tiếp nhận/phân tích bài toán kinh doanh, lựa chọn kiến trúc mô hình, huấn luyện, đánh giá hiệu năng (Metrics Evaluation) đến xây dựng hệ thống báo cáo phân tích.
Phát triển tư duy Storytelling, đóng gói sản phẩm công nghệ dưới dạng Dashboard tương tác trực quan; rèn luyện khả năng phản biện, phối hợp nhóm và giải trình giải pháp AI bằng dữ liệu thực tế.
Bứt phá năng lực với các kiến trúc AI tiên tiến nhất hiện nay: Thị giác máy tính (CV), Xử lý ngôn ngữ tự nhiên (NLP), Học tăng cường (RL), các mô hình ngôn ngữ lớn (LLMs), cấu trúc Transformer, AI Agents, GAN và Diffusion Models.
Thành thạo kiến trúc framework Học sâu hàng đầu (TensorFlow, PyTorch) ; tối ưu hóa mô hình với ONNX, Quantization, Pruning nhằm tăng tốc độ xử lý; bước đầu làm quen với xử lý dữ liệu lớn thông qua PySpark.
Đóng gói mô hình AI qua các API hiệu năng cao (FastAPI/Flask), triển khai linh hoạt lên môi trường Cloud/Edge devices, xây dựng hoàn chỉnh Pipeline AI ứng dụng thực tế trong Chatbot thông minh, trích xuất hóa đơn (OCR), Y tế số...
Tích hợp toàn bộ kiến thức toàn khóa để thiết kế, tối ưu và bảo vệ thành công đồ án tốt nghiệp giải quyết bài toán thực tế của doanh nghiệp. Đóng gói sản phẩm lên GitHub để xây dựng hồ sơ năng lực (Portfolio) vượt trội, sẵn sàng chinh phục các nhà tuyển dụng trong và ngoài nước.
Đối tượng học tập
Chuẩn đầu ra
Sau khi hoàn thành khóa học AI Engineer bạn sẽ:
Sau khi hoàn thành khóa học AI Engineer bạn sẽ:
Biết:
- Các khái niệm cốt lõi trong trí tuệ nhân tạo, Machine Learning, Deep Learning, NLP, Computer Vision, Generative AI.
- Cách hoạt động và ứng dụng thực tiễn của các mô hình AI trong doanh nghiệp.
Hiểu:
- Quy trình phát triển hệ thống AI: từ xử lý dữ liệu, chọn thuật toán, huấn luyện, đánh giá đến triển khai sản phẩm.
- Đặc điểm, ưu nhược điểm và cách chọn mô hình phù hợp với từng loại bài toán (classification, regression, clustering,...).
Áp dụng:
- Thiết kế pipeline AI hoàn chỉnh và triển khai mô hình vào môi trường production (web/API/cloud/edge).
- Tối ưu mô hình AI bằng các kỹ thuật nâng cao như quantization, pruning, model conversion (ONNX).


Bạn sẽ thành tạo công cụ phổ biến của AI Engineer:
Bạn sẽ thành tạo công cụ phổ biến của AI Engineer:
Công cụ xử lý Big Data:
Pandas, NumPy, PySpark
Mô hình học máy / học sâu:
TensorFlow, PyTorch, Keras
Thị giác máy tính (CV):
OpenCV, CNN (ResNet, EfficientNet), YOLO
Xử lý ngôn ngữ tự nhiên (NLP):
BERT, Word2Vec, GloVe, Transformer, Hugging Face
Triển khai AI:
Flask, FastAPI, Docker, Triton Inference Server, ONNX
Cloud / Infra:
AWS, GCP, Azure, Raspberry Pi, Jetson
Theo dõi & tối ưu mô hình:
TensorBoard, Early Stopping, Regularization, GridSearch
Generative AI:
GAN, Diffusion Models, ComfyUI
AI Agent & LLMs:
LLM cơ bản, agentic AI workflow
Thực hành dự án thật, ứng dụng cao:
Thực hành dự án thật, ứng dụng cao:
Dự án 1:
Xây dựng hệ thống phân loại ảnh y tế bằng Deep Learning, triển khai model trên cloud với giao diện web/API.
Dự án 2:
Thiết kế chatbot hỗ trợ khách hàng sử dụng NLP và mô hình ngôn ngữ BERT, tích hợp qua Telegram hoặc Web UI.
Dự án 3:
Phân tích hóa đơn và trích xuất thông tin bằng OCR + KIE, xây dựng pipeline Document AI end-to-end.
Dự án 4 (tùy chọn):
Ứng dụng mô hình Generative AI (Diffusion, LLMs) cho tạo nội dung hoặc phân tích dữ liệu doanh nghiệp.

Lộ trình học tập
- Biến và các kiểu dữ liệu.
- Input & print trong Python.
- Biểu thức điều kiện.
- Áp dụng các kiểu dữ liệu nào trong thực tế?
- Vòng lặp For, While
- Tự động hóa các tác vụ lặp đi lặp lại
- Khởi tạo List
- Truy cập phần tử trong List (truy cập bằng index, truy cập đầu cuối danh sách)
- Thao tác trên List (Thêm, xóa, thay đổi giá trị phần tử)
- Cắt (slicing) List
- Các phương thức List (sort(), reverse(), count(), index(), extend())
Các thao tác trên Tuple
- Cú pháp để tạo tuple bằng dấu ngoặc tròn ()
- Truy cập phần tử trong Tuple
- Thao tác với Tuple
- Ứng dụng của Tuple
- Tuple packing và unpacking
- Khởi tạo và thao tác trên Dictionaries và Sets
- Ứng dụng của Dictionaries và Sets
- Gọi hàm trong python
- Biến cục bộ và biến toàn cục
- Hàm lambda
- Phương thức
- Package và import
Thực hành: lớp và đối tượng
- Đối tượng Groupby
- Làm việc với DataFrame
- Chèn, xóa, sửa dòng và cột trong DataFrame
- Sắp xếp dữ liệu trong DataFrame
- Các biểu đồ cơ bản
- Lợi ích của Seaborn
- Biểu đồ trong Seaborn
- Broadcasting
- Vectorization & performance
- Dot product, matrix ops trong NumPy
- Liên hệ với ML (loss, gradient)
- Làm sạch dữ liệu
- Thống kê mô tả
- Vẽ biểu đồ
- Viết báo cáo notebook
- Không gian vector và đặc trưng dữ liệu
- Độ dài vector (norm) và khoảng cách giữa các vector
- Tích vô hướng (dot product) và ý nghĩa hình học
- Cosine similarity và đo độ tương đồng giữa dữ liệu
- Ma trận như một phép biến đổi tuyến tính trong mô hình học máy
- Linear Transformation
- Đạo hàm và ý nghĩa của đạo hàm trong tối ưu hóa
- Gradient của hàm nhiều biến
- Hàm mục tiêu (objective function) trong bài toán tối ưu
- Gradient Descent và nguyên lý cập nhật tham số
- Local minimum và global minimum
- Vai trò của nhiễu (noise) và phương sai trong dữ liệu
- Các loại học máy: Supervised, Unsupervised
- Regression và Classification
- Bài toán học máy trong thực tế
- Quy trình Machine Learning tổng quát
- Vai trò của dữ liệu trong học máy
- Dữ liệu có nhãn và vai trò của nhãn
- Quy trình học có giám sát
- Thuật toán K-Nearest Neighbors (KNN)
- Khoảng cách giữa các mẫu dữ liệu
- Ưu điểm và hạn chế của KNN
- So sánh KNN với các mô hình tham số
- Nguyên lý của KNN
- Lựa chọn số lượng hàng xóm K
- Ưu điểm và hạn chế của KNN
- Curse of dimensionality
- Ứng dụng KNN trong thực tế
- Feature vector và không gian đặc trưng
- Chuẩn hoá và scale dữ liệu
- Train / Validation / Test split
- Encoding dữ liệu dạng categorical
- Feature selection và feature extraction
- Ảnh hưởng của feature tới hiệu quả mô hình
- Mô hình tuyến tính và hàm dự đoán
- Hàm mất mát MSE
- Huấn luyện Linear Regression bằng Gradient Descent
- Bài toán phân loại nhị phân
- Hàm sigmoid trong Logistic Regression
- Decision boundary
- Hàm mất mát Cross-Entropy
- So sánh Linear Regression và Logistic Regression
- Ứng dụng hồi quy và phân loại trong thực tế
- F1-score
- Confusion Matrix
- ROC Curve và AUC
- Đánh giá mô hình trong bối cảnh thực tế
- Bias – Variance tradeoff
- Regularization (L1, L2)
- Early stopping
- Data leakage
- Chiến lược cải thiện khả năng tổng quát hoá
- Ý tưởng tìm siêu phẳng phân tách dữ liệu
- Margin và vai trò của margin trong phân loại
- Support vectors
- Kernel và ánh xạ dữ liệu sang không gian đặc trưng
- Ưu điểm và hạn chế của Support Vector Machine
- Cấu trúc mô hình Decision Tree
- Tiêu chí chia nhánh (Gini, Entropy)
- Overfitting trong Decision Tree
- Ưu điểm và hạn chế của Decision Tree
- Sự khác biệt giữa Supervised và Unsupervised Learning
- Bài toán phân cụm dữ liệu
- Ứng dụng Unsupervised Learning trong thực tế
- Thách thức khi không có nhãn dữ liệu
- Nguyên lý thuật toán K-means
- Khoảng cách và tâm cụm (centroid)
- Khởi tạo K-means
- Lựa chọn số lượng cụm K
- Ưu điểm và hạn chế của K-means
- Ứng dụng phân cụm dữ liệu
- Bagging và Boosting (ý tưởng)
- Random Forest
- Vì sao kết hợp nhiều mô hình lại hiệu quả
- So sánh model đơn và ensemble
- Ứng dụng ensemble trong thực tế
- Ảnh hưởng của hyperparameter tới mô hình
- Grid Search
- Random Search
- Overfitting trong quá trình tuning
- Chiến lược chọn mô hình tốt
- Mạng nơ-ron nhiều lớp
- Activation function
- Vai trò phi tuyến trong Neural Network
- Giới hạn của Perceptron (bài toán XOR)
- Universal Approximation (ý tưởng: NN đủ lớn có thể xấp xỉ hàm bất kỳ)
- So sánh Neural Network và mô hình tuyến tính
Thực hành: so sánh decision boundary giữa Logistic Regression và Neural Network
- Chu trình huấn luyện Neural Network
- Computational graph
- Backpropagation (ý tưởng)
- Gradient Descent trong Neural Network
- Vanishing và Exploding Gradient
- Regularization trong Neural Network
Thực hành: huấn luyện Neural Network đơn giản từ đầu
- Cross-validation thực tế
- Random seed, reproducibility
- Giới thiệu MLflow / Weights & Biases (concept)
- Churn prediction
- Credit scoring
- Recommendation cơ bản
Phân tích:
- Dữ liệu
- Mô hình
- Metric
- Trade-off
- So sánh các nhóm mô hình học máy
- Chiến lược lựa chọn mô hình phù hợp
- Liên hệ Machine Learning với Deep Learning
- Chuẩn bị cho Computer Vision và NLP
- Trình bày bài thực hành
Kiến thức mở rộng: Giới thiệu Vision Transformer (ViT), ConvNeXt, EfficientNetV2 – vì sao các model này chiếm ưu thế trong doanh nghiệp (nhẹ, tốc độ nhanh, inference tốt). Trình bày ví dụ real-world: Google Lens, FaceNet nhận diện khuôn mặt.
Code: Áp dụng torchvision transforms; thử 2 pipeline augmentation; mô tả cách chọn LR scheduler. Bài tập bổ trợ:
- Yêu cầu: So sánh performance giữa “no augmentation” vs “strong augmentation”
- Mục đích: Hiểu tầm quan trọng của augmentation & regularization
- Class imbalance
- Error analysis (FP/FN)
- Dataset bias trong CV
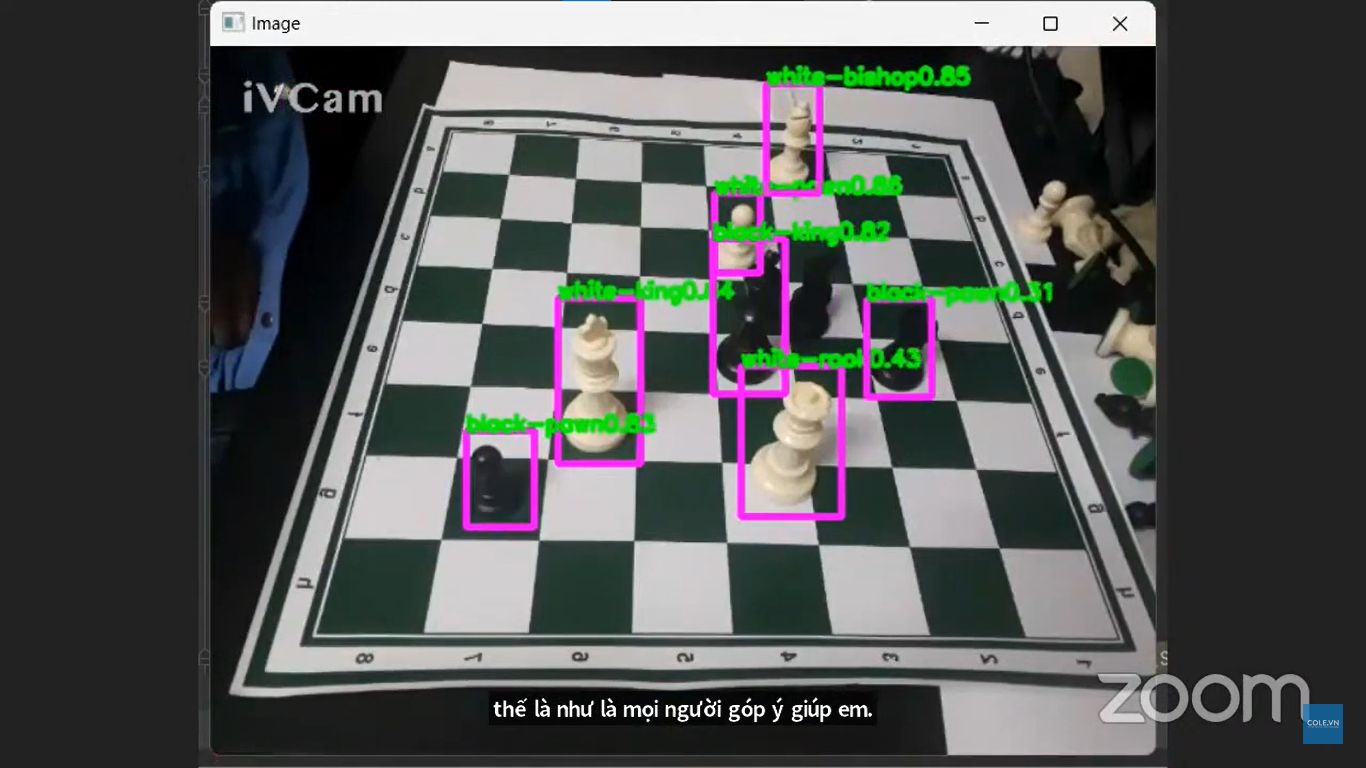
- mAP cho bài toán object detection
Kiến thức mở rộng: Giới thiệu các mô hình phổ biến: ResNet
- Giới thiệu PyTorch
- Xây CNN đơn giản (PyTorch), train nhanh trên CIFAR-10, hiển thị loss/accuracy.
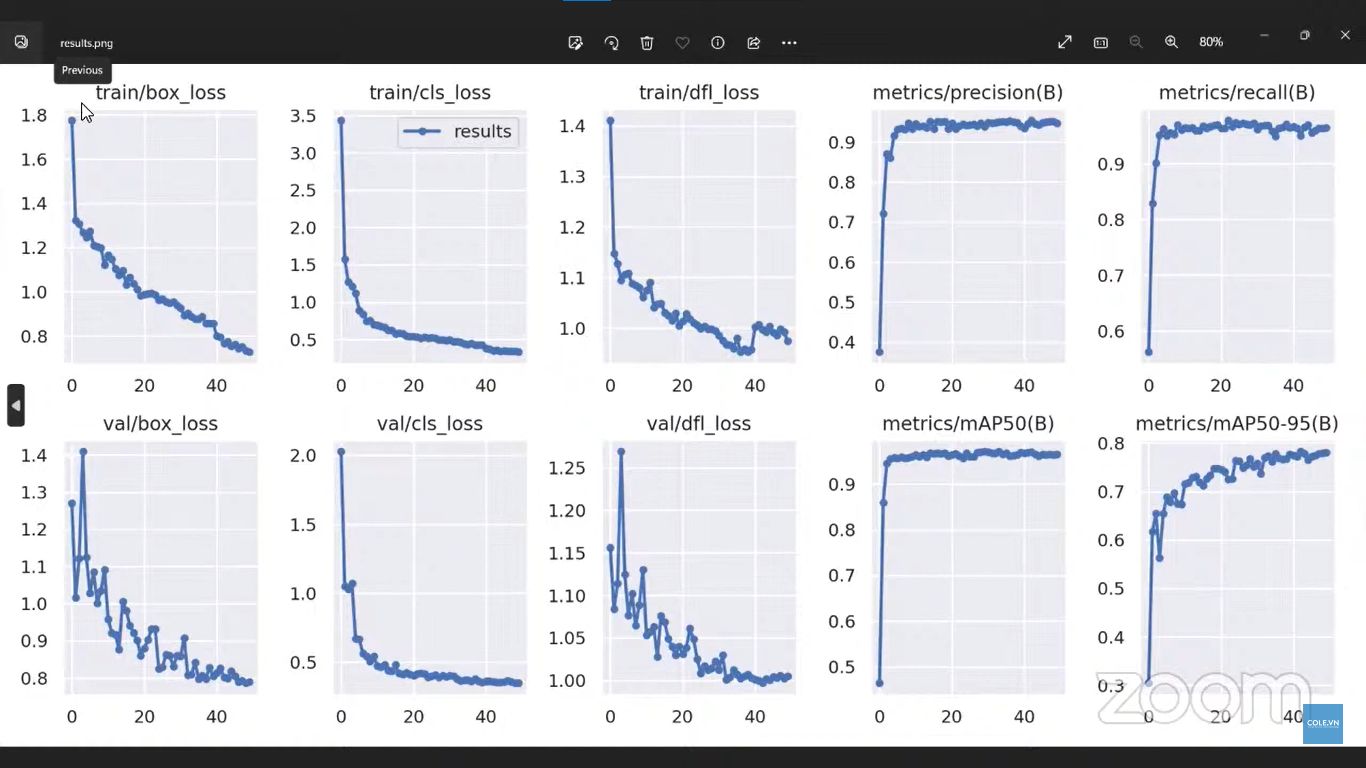
Yêu cầu: Thực hành trên Colab baseline CNN, train trên CIFAR-10 ít nhất 3 epoch, nộp file notebook + ảnh loss/accuracy curve.
Mục đích: Ôn lại pipeline training và đọc kết quả.
Mở rộng: Tham khảo implement mô hình ResNet với PyTorch
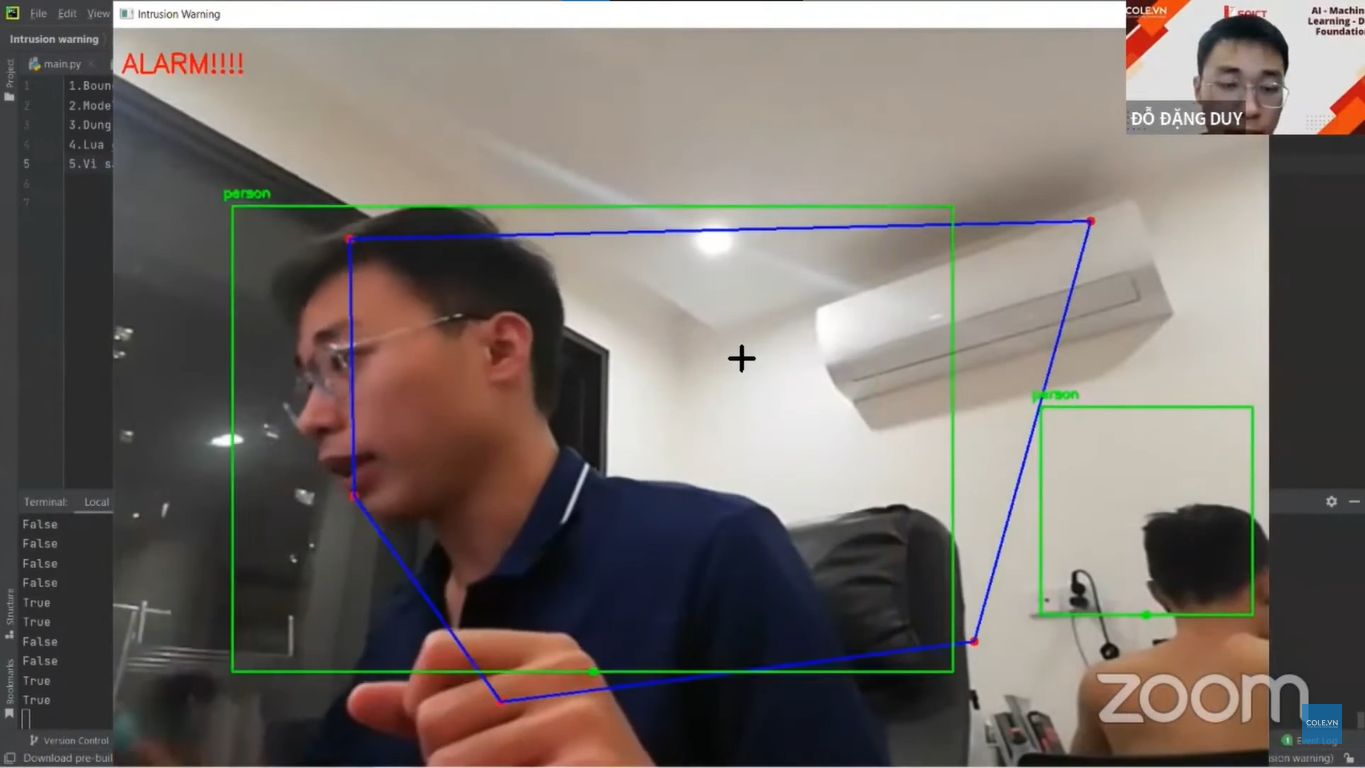
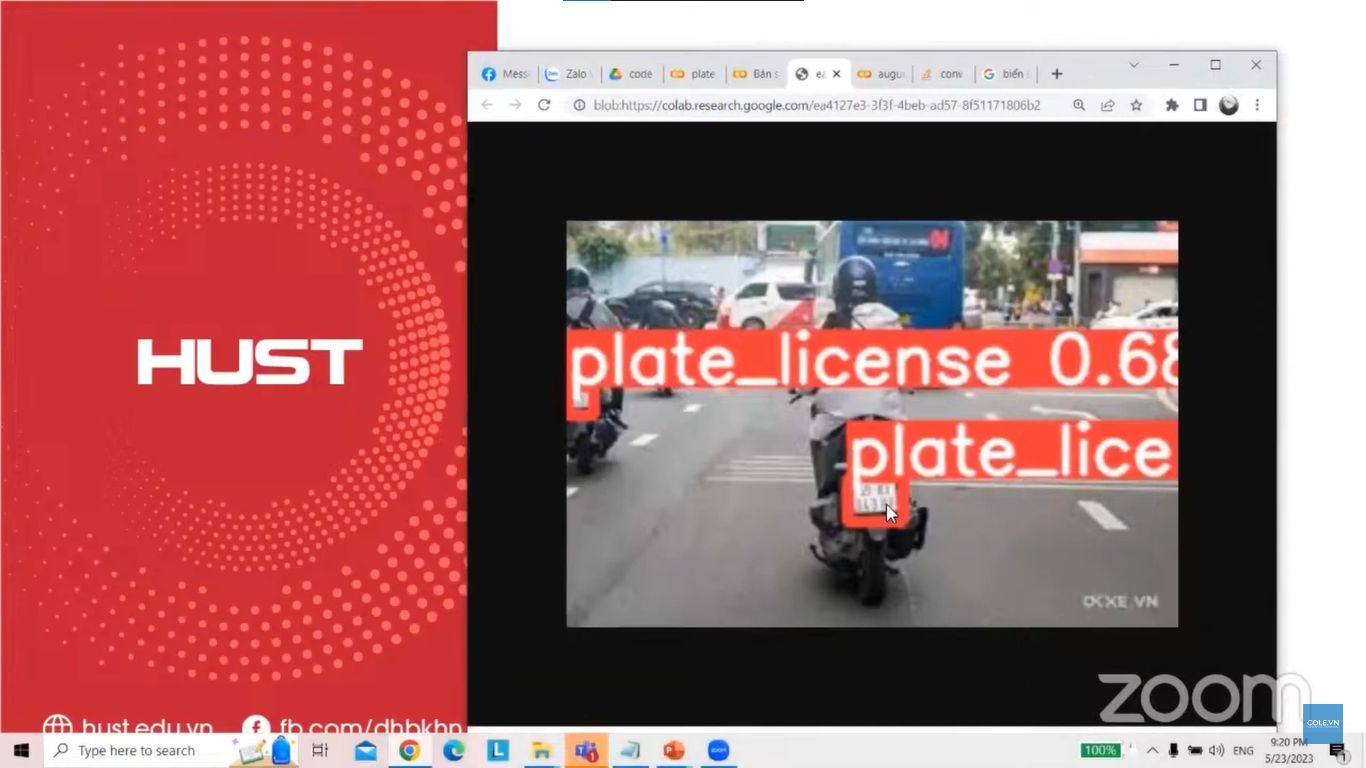
Kiến thức mở rộng: Giới thiệu SOTA: YOLOv10-12, DETR (Transformer-based detection)
- Huấn luyện và so sánh 2 mô hình RetinaNet và YOLOv10-12 trên 1 dataset của Roboflow
- Báo cáo so sánh: training time, inference time, accuracy, nhận xét trade-off giữa 2 mô hình
Kiến thức mở rộng: Các mô hình unsupervised segmentation như Segment Anything Model
Mở rộng: chạy thử mô hình SAM-3 cho ảnh y tế
- Quantization (int8)
- Inference speed vs accuracy
- CV trên edge device (Jetson, mobile)
Code: dùng Hugging Face tokenizers, demo word2vec/fastText toy
Bài tập bổ trợ:
- Yêu cầu: So sánh embedding trung bình (word2vec) và contextual embedding (BERT) trên 10 câu mẫu
- Mục đích: Hiểu sự khác biệt giữa biểu diễn tĩnh và biểu diễn theo ngữ cảnh
Kiến thức mở rộng: Giới thiệu hành trình phát triển NLP từ rule-based → statistical → neural → LLMs Trình bày ứng dụng NLP trong doanh nghiệp: chatbot CSKH, phân tích cảm xúc, xử lý tài liệu.
Code: mini-Transformer implementation (toy) hoặc visualize attention
Code: fine-tune BERT on sentiment classification / NER using Hugging Face
Kiến thức mở rộng: Giới thiệu các kỹ thuật fine-tuning hiệu quả cho NLP: Adapter Tuning, Prefix/Prompt Tuning, và LoRA (chỉ ở mức khái niệm). Trình bày ứng dụng thực tế: sentiment analysis, legal doc classification, spam filtering
- Label noise
- Bias trong dữ liệu text
- Confusion matrix cho NLP
Code: Sinh văn bản bằng mô hình GPT nhỏ (HF pipeline); so sánh các phương pháp decoding
Bài tập bổ trợ:
- Yêu cầu: Tạo 3 câu chuyện ngắn với top-k = 30, top-p = 0.9, beam = 5; so sánh độ tự nhiên của kết quả
- Mục đích: Hiểu ảnh hưởng của chiến lược decoding lên chất lượng văn bản sinh ra
Kiến thức mở rộng: Giới thiệu các ứng dụng Text Generation trong doanh nghiệp: tóm tắt tự động, sinh tiêu đề sản phẩm, sinh phản hồi email. Nói về các hướng phát triển control generation (controllable style, sentiment).
Code: Xây notebook đánh giá và so sánh hai model bằng Hugging Face pipeline
Kiến thức mở rộng: Giới thiệu thực tiễn triển khai NLP trong doanh nghiệp: mô hình phục vụ API, hệ thống tìm kiếm (semantic search), và quy trình cập nhật model định kỳ. Chia sẻ cách doanh nghiệp đánh giá mô hình NLP theo tiêu chí thực tế (accuracy vs latency vs cost).
Code: Demo hệ thống QA hoặc NER trên domain cụ thể.
- BM25 intuition
- Dense vs sparse retrieval
- Semantic search pipeline
Code: Tạo embedding cho vài văn bản bằng model nhỏ (HF/OpenAI), index vào FAISS, truy vấn nearest neighbors
Bài tập bổ trợ:
- Yêu cầu: Chọn 3-5 tài liệu PDF/text ngắn, thực hiện chunk → embedding → index vào FAISS/Chroma; chạy 10 truy vấn, nộp top-3 results + file index script.
- Mục đích: Hiểu embedding và tìm kiếm vector cơ bản.
Code: Pipeline: chunk văn bản → tạo embeddings → lưu vào Chroma/FAISS → retrieve + gắn prompt
Kiến thức mở rộng: Giới thiệu các mô hình RAG doanh nghiệp hay dùng (LlamaIndex, LangChain, Haystack). Nêu ví dụ thực tế: chatbot tư vấn sản phẩm, hỏi–đáp nội bộ tài liệu
Code: Thử 3 prompt templates cho cùng 1 query, so sánh output; thêm context retrieved vào prompt. Xây mini-app LangChain: RAG + 1 tool; demo memory ngắn hạn
Bài tập bổ trợ (nếu có):
- Yêu cầu: Với cùng dataset, viết 3 prompt template (concise, few-shot, context-rich); cho 15 câu hỏi test, đánh giá output theo: factuality (0/1), relevance (0–2). Nộp bảng kết quả và bình luận ngắn
- Mục đích: Hiểu ảnh hưởng của prompt và cách giảm hallucination bằng grounding
Code: Deploy minimal API (FastAPI) bọc RAG pipeline; thêm caching đơn giản
- Faithfulness
- Answer relevance
Human eval vs automatic eval
Logging & tracing
RAG failure patterns
LangSmith for observation
Code: Giảng viên hướng dẫn và chạy mẫu project hoàn chỉnh: ingest PDF → chunk → tạo embedding → lưu vector DB → xây API trả lời → UI (Streamlit/Gradio). Giải thích từng thành phần và cách mở rộng (thêm metadata, rerankers, multi-source)
- Multi-hop RAG
- Tool-augmented RAG
- Multi-agent RAG (overview)
Code: Cài đặt Q-learning tabular trên FrozenLake hoặc GridWorld (Gym)
Kiến thức mở rộng: Giới thiệu lịch sử phát triển RL, ứng dụng trong game (AlphaGo, Atari) và tối ưu hóa vận hành. Trình bày các thuật toán cơ bản khác: SARSA, Monte Carlo
Code: Implement DQN cho CartPole-v1 (PyTorch hoặc Stable-Baselines3)
Bài tập bổ trợ:
- Yêu cầu: Thử thay đổi network size hoặc learning rate, quan sát ảnh hưởng đến reward trung bình
- Mục đích: Hiểu ảnh hưởng hyperparameter lên hiệu năng
Code: Fine-tune DQN / chạy MountainCar-v0 và thử reward shaping đơn giản
Kiến thức mở rộng: Trình bày ứng dụng RL trong tối ưu vận hành & ra quyết định doanh nghiệp: dynamic pricing, quảng cáo, quản lý kho, logistics
Code (GV hướng dẫn): Làm mẫu project: Inventory management / Traffic signal / Grid navigation
Hoạt động nhóm: Trình bày mô hình → nhận phản hồi từ lớp
Mở rộng: Giới thiệu các ứng dụng Multi-Agent RL (robot swarm, trading bots, supply chain optimization)
Hoạt động nhóm: Thảo luận “Khi nào giải thích mô hình gây hiểu lầm?”
Mở rộng: Ứng dụng Explainable AI trong y tế, tài chính
Hoạt động nhóm: Chỉnh dataset hoặc weight loss để giảm bias, ghi lại kết quả
Kiến thức mở rộng: Case studies nổi bật — COMPAS (justice bias), Amazon Hiring model (gender bias), AI Ethics tại Google & Meta
Hoạt động nhóm: Thiết kế AI Governance Dashboard mô phỏng — theo dõi fairness, drift, explainability và compliance
Kiến thức mở rộng: Giới thiệu khung AI Act (EU), ISO/IEC 42001 (AI Management System), và các quy định nổi bật (GDPR, DPDP)
Giảng viên

Giảng viên Khoa học máy tính - ĐH Ngoại Thương TP.HCM
Học vấn & chuyên môn:
• Tiến sĩ Khoa học Tính toán, chuyên sâu trong các lĩnh vực Mô phỏng số, Khoa học dữ liệu và Ứng dụng kỹ thuật.
Kinh nghiệm giảng dạy & công tác:
• Giảng viên Đại học Ngoại Thương TP. Hồ Chí Minh – giảng dạy Toán ứng dụng và Khoa học máy tính (3+ năm).
• Giảng viên Đại học Bách khoa TP. Hồ Chí Minh – Khoa Kỹ thuật Hàng không Vũ trụ và Giao thông Vận tải (3+ năm).
• Nghiên cứu viên tại Viện Năng lượng Ứng dụng – NUPEC (Nuclear Power Engineering Center), Tokyo, Nhật Bản (4+ năm).
• Kỹ sư CNTT tại DFM-Engineering (5+ năm).
• Hơn 10 năm nghiên cứu trong lĩnh vực Khoa học tính toán và Phân tích dữ liệu.
Thành tựu & đóng góp:
• Tham gia nhiều dự án nghiên cứu ứng dụng mô phỏng tính toán và phân tích dữ liệu năng lượng tại Nhật Bản.
• Giảng dạy, hướng dẫn nhiều khóa học chuyên sâu về Khoa học dữ liệu, mô hình hóa tính toán và các phương pháp tính toán kỹ thuật.
.png)
Chuyên gia Trí tuệ nhân tạo, Học máy & Hệ thống tính toán hiệu năng cao
Học vấn
- Cử nhân CNTT – Đại học Bách Khoa Hà Nội (2002)
- Thạc sĩ CNTT – Viện Tin học Pháp ngữ (IFI) (2005)
- Tiến sĩ CNTT – Đại học Blaise Pascal, Pháp (2012)
Kinh nghiệm giảng dạy & công tác
- Giảng viên Đại học Bách Khoa Hà Nội.
- Trưởng khoa CNTT – Đại học Greenwich Việt Nam (liên kết Đại học FPT & Đại học Greenwich UK).
- Hơn 20 năm kinh nghiệm giảng dạy, nghiên cứu và quản lý học thuật trong lĩnh vực CNTT.
- Chuyên môn: Trí tuệ nhân tạo (AI), Machine Learning, Công nghệ phần mềm, Hệ thống phân tán và Cấu trúc dữ liệu.
Hoạt động nghiên cứu & dự án khoa học
- Thành viên nhóm nghiên cứu VNGrid (2010).
- Đề tài hợp tác quốc tế về nghiên cứu hệ thống tính toán hiệu năng cao và mô phỏng vật liệu vi mô (2009).
- Hợp tác nghiên cứu và chuyển giao công nghệ với Centre for Development of Advanced Computing (Ấn Độ) (2014).
- Tham gia dự án EuAsiaGrid – xây dựng cổng thông tin gINFO Portal (2011).
- Đề tài nghiên cứu dịch vụ tin sinh trên nền điện toán đám mây cho các bài toán siêu bộ gen (2015–2016).
Thành tựu & công bố
- Công bố nhiều bài báo khoa học quốc tế về học sâu, hệ thống thông minh, nhận diện hình ảnh và xử lý thông tin.
- Các ứng dụng tiêu biểu: nhận diện thẻ căn cước, nhận dạng biển báo giao thông và hệ thống học máy phân tích dữ liệu lớn.

Machine Learning Team Lead – GMO Runsystem
Học vấn:
• Thạc sĩ Khoa học Dữ liệu – Đại học Bách Khoa Hà Nội.
Kinh nghiệm công tác:
• Machine Learning Team Lead – GMO Runsystem: Dẫn dắt đội ngũ triển khai các hệ thống AI cho doanh nghiệp Nhật.
• Từng công tác tại FPT Smart Cloud và Sun Asterisk, phụ trách mảng AI ứng dụng và xử lý dữ liệu lớn.
• 5+ năm kinh nghiệm triển khai sản phẩm AI trong các lĩnh vực KYC, OCR, Smart Agent, hiểu văn bản & trợ lý doanh nghiệp.
Chuyên môn kỹ thuật:
• Thành thạo: Llama-cpp, LangChain, FastAPI, HuggingFace, FAISS, Docker.
• Kinh nghiệm phát triển và huấn luyện mô hình ngôn ngữ (LLMs), ứng dụng AI trong quy trình tự động hóa doanh nghiệp.
Thành tựu & nghiên cứu:
• Best Paper Award – MAPR 2023.
• Đạt thứ hạng cao tại các cuộc thi AI quốc tế: ICDAR 2021, RIVF 2021.
• Tác giả nhiều mô hình AI đang được ứng dụng thực tế tại các doanh nghiệp Nhật Bản.

Tiến sĩ Khoa học Máy tính
Học vấn & chuyên môn:
• Tiến sĩ Khoa học Máy tính – Đại học Lorraine, Pháp.
• Nghiên cứu sinh tại Google Research Zurich.
• Giảng viên cao học chương trình Erasmus Mundus tại Pháp.
Kinh nghiệm công tác & tư vấn:
• Data & AI Manager Consultant: Tư vấn chiến lược dữ liệu & triển khai AI cho doanh nghiệp trong lĩnh vực giao dịch, thị trường và vận hành.
• Lead Data Scientist – Zalo: Phát triển hệ thống Recommendation System cho Zing MP3 và Zalo Short Video, ứng dụng mô hình học sâu trong môi trường dữ liệu real-time.
• Senior Data Scientist – MoMo: Thiết kế & tối ưu hệ thống Recommendation & Engagement Engine bằng Reinforcement Learning.
• Senior Data Scientist – Geniebook (Singapore): Phát triển hệ thống AI chấm điểm và gợi ý học liệu cá nhân hóa.
• Applied Scientist – Myli.io (Pháp): Ứng dụng NLP & Computer Vision cho hệ thống hội thoại trong lĩnh vực nhà hàng – bán lẻ châu Âu.
Thành tựu & nghiên cứu:
• Công bố nghiên cứu tại các hội nghị AI hàng đầu: AAAI, COLING, ICANN, cùng nhiều hội thảo quốc tế khác.
• Reviewer được mời tại các hội nghị chuyên ngành NLP & Deep Learning.
• Mentor và hướng dẫn luận văn cao học tại châu Âu.
• Thành viên các học viện AI uy tín: Google PhD NLP Summit, Deep Learning & Reinforcement Learning Summer School – Vector Institute (Canada), FADEx France–US AI Seminar.
.png)
AI Leader & Senior AI Engineer
Học vấn:
• Cử nhân Khoa học Máy tính – Đại học Công nghệ, Đại học Quốc gia Hà Nội (2009–2013)
• Thạc sĩ Khoa học Máy tính – Đại học Công nghệ, Đại học Quốc gia Hà Nội (2013–2016)
• Nghiên cứu sinh tại University of Technology Sydney
• 8 + công bố quốc tế ISI Q1/Q2
Kinh nghiệm & chuyên môn:
• Founder & CEO LingoLab Vietnam – startup phát triển giải pháp AI cho luyện thi ngôn ngữ (2025–nay).
• COO & AI Technical Lead tại FIMO JSC – phụ trách chiến lược kỹ thuật và triển khai AI cho các bài toán dữ liệu không gian (2021–2025).
• Mentor AI & Startup tại FPT FUNiX – hướng dẫn học viên triển khai dự án AI ứng dụng và tư duy khởi nghiệp công nghệ (2021–2022).
• 10+ năm kinh nghiệm nghiên cứu, phát triển và triển khai hệ thống AI/ML trong môi trường doanh nghiệp và startup.
• Từng đảm nhiệm các vị trí: Senior AI Engineer, AI Lead, Data Scientist tại AIMENEXT, Mfunctions, VinCommerce dẫn dắt đội ngũ xây dựng và triển khai các giải pháp AI cốt lõi, từ R&D đến production, bao gồm hệ thống AI cho NLP, Computer Vision, dữ liệu lớn và hệ thống thông minh.
Hoạt động nghiên cứu & dự án:
• Tham gia các dự án trọng điểm cấp Nhà nước như Chương trình KC4.0 và KHCN Vũ trụ, đảm nhiệm vai trò nghiên cứu và triển khai các bài toán AI trong thực tiễn.
• Hợp tác nghiên cứu quốc tế với nhiều đơn vị và nhóm nghiên cứu nước ngoài, tham gia công bố các kết quả trên tạp chí ISI Q1/Q2.
• Đạt Top 5 toàn cầu tại cuộc thi Data Fusion Contest 2017 do IEEE GRSS tổ chức.
• Nhận các học bổng danh giá như UTS–VNU, Erasmus+ và Toshiba, ghi nhận thành tích học thuật và năng lực nghiên cứu nổi bật.
Dự án học viên
Feedback học viên

Nguyễn Linh Đan
Ai Engineer tại Sun Group

Phạm Thanh Hoa
Leader AI Engineer tại Chứng khoán Bảo việt

Nguyễn Thái Lực
Data Science tại LB Bank
Lợi ích chỉ có tại COLE
Giới thiệu việc làm sau khóa học
Học lại free
Cộng đồng chuyển đổi số 1
Câu hỏi thường gặp
Để biết thêm thông tin chi tiết đừng ngần ngại gọi cho chúng tôi.
-
Hotline
-
Email
-
Trang tin chính thức
Hoặc để lại thông tin

COLE - Lựa chọn hàng đầu cho nhân
sự về Digital Skills

5000+
Học viên theo học

30%
Thu nhập học viên tăng lên sau khi học

30+ Khóa học
Hàng đầu về ứng dụng công nghệ

50+
Chuyên gia hàng đầu về chuyển đổi số
300+ Doanh nghiệp hàng đầu lựa chọn Cole để nâng cấp kỹ năng
Hình ảnh lớp học