Khóa Học Data Engineer & Big Data 2026 – Airflow, Spark, Kafka Thực Chiến


Thời lượng
63 buổi

Hình thức đào tạo
Online qua Zoom

Học phí
Liên hệ
Tổng quan nghề Data Engineer
Chương trình đặc biệt phù hợp cho những ai đang tìm kiếm:
- Khóa học Data Engineer, đào tạo từ cơ bản đến nâng cao, có mentor hướng dẫn.
- Khóa học Big Data Engineer giúp làm chủ hệ sinh thái dữ liệu hiện đại.
- Khóa học kỹ sư dữ liệu có tính ứng dụng thực tế cao, học online mọi lúc mọi nơi.
- Data Engineer khóa học dành cho người mới hoặc đã có nền tảng lập trình/CNTT.
- Khóa học data engineering giúp triển khai pipeline dữ liệu phục vụ phân tích và AI.
Tổng quan thị trường lao động ngành Data Engineering
Trong giai đoạn 2025–2030, kỹ sư dữ liệu Data Engineer được dự báo là một trong những nghề có tốc độ tăng trưởng nhanh nhất trong ngành công nghệ. Nhu cầu tuyển dụng các vị trí liên quan đến xử lý dữ liệu, hạ tầng dữ liệu và Big Data tăng trưởng đều đặn trên 35–40% mỗi năm, đặc biệt tại các quốc gia đang đẩy mạnh chuyển đổi số như Mỹ, Đức, Singapore, Ấn Độ và Việt Nam.Hiện nay, mức lương của Data Engineer nằm trong top đầu ngành CNTT, dao động từ 60.000 đến 130.000 USD/năm trên thị trường quốc tế, và từ 20 đến 60 triệu đồng/tháng tại Việt Nam – tùy theo kinh nghiệm, vị trí và năng lực công nghệ.
Tuy nhiên, thực tế cho thấy nguồn nhân lực thành thạo hệ sinh thái dữ liệu hiện đại vẫn còn rất thiếu, đặc biệt là những người có thể làm việc với pipeline, kiến trúc phân tán và công cụ như Airflow, dbt, Spark... Đặc biệt khi AI đang tiêu thụ dữ liệu với tốc độ chưa từng có, người biết xây và vận hành hạ tầng dữ liệu từ pipeline, data warehouse đến data lake house — sẽ không bao giờ lo thiếu việc. Nhu cầu đặc biệt bùng nổ với những Data Engineer chuyên sâu về Cloud Infrastructure và Streaming, nhóm này đang nhận mức đãi ngộ vượt trội so với mặt bằng chung.
Vì vậy, việc tham gia các khóa học Data Engineer bài bản, có hướng dẫn thực chiến và cập nhật công nghệ mới nhất, đang trở thành chiến lược then chốt để đón đầu xu hướng và bứt phá sự nghiệp trong lĩnh vực dữ liệu.

Những xu hướng chính trong lĩnh vực Big Data Engineer có thể kể đến bao gồm:
Lợi ích khóa học
Thời lượng
8 tháng - 60 buổi (Lý thuyết + thực hành dự án thực chiến dữ liệu thật)
Hình thức học
Online qua nền tảng Zoom/Microsoft Teams
Lịch khai giảng
- Hàng tháng
- Thời gian học: Từ 20h- 22h
Công cụ
Có LMS hỗ trợ video, record, Slide, Test đánh giá năng lực và nhiều tài liệu học tập khác
Chứng nhận
Được cấp bởi Sở GDĐT Hà Nội chứng nhận hoàn thành khóa học
Hỗ trợ
Hỗ trợ trọn đời sau khóa học & hệ thống học tập video record LMS
Mục tiêu học tập
Đối tượng học tập
Chuẩn đầu ra – Năng lực sau khóa học
Kiến thức & kỹ năng chuyên môn
Kiến thức & kỹ năng chuyên môn
• Hiểu rõ vai trò của Data Engineer trong hệ thống dữ liệu doanh nghiệp và môi trường Big Data.
• Thành thạo các công nghệ cốt lõi: SQL, Data Warehouse, ETL/ELT, Power BI, Cloud (AWS), Hadoop, Spark, Kafka, Airflow...
• Làm chủ toàn bộ quy trình xây dựng và vận hành hệ thống dữ liệu: từ thiết kế CSDL, xử lý dữ liệu, đến trực quan hóa và triển khai hệ thống.
• Làm quen cấu trúc đề và thực hành các chứng chỉ phổ biến: Databricks, AWS Data Analytics, Azure Data Engineer…


Thực chiến với hệ thống dự án
Thực chiến với hệ thống dự án
• Hoàn thành 7+ dự án thực tế, bao gồm: thiết kế cơ sở dữ liệu, xây dựng Data Warehouse, ETL pipeline, phân tích dữ liệu lớn, xử lý dữ liệu thời gian thực và triển khai hệ thống trên AWS, Iceberg, MinIO.
Năng lực làm việc & ứng dụng thực tế
Năng lực làm việc & ứng dụng thực tế
• Phân tích yêu cầu, thiết kế hệ thống dữ liệu và tối ưu hóa quy trình xử lý dữ liệu doanh nghiệp.
• Kỹ năng làm việc nhóm, tư duy hệ thống, tự học công nghệ mới và triển khai dự án theo mô hình Agile.
• Viết CV, luyện phỏng vấn và sẵn sàng ứng tuyển vào các vị trí Data Engineer, Big Data Engineer, BI Developer tại doanh nghiệp trong và ngoài nước.

Lộ trình học tập
- Data Warehousing
- ETL
- SQL
- Business Intelligence
- SQL Server
- Framework ETL, ELT
- AWS
- Big Data
- Cài đặt Microsoft SQL Server
- Cài đặt Tool SSMS
- Cơ sở của truy vấn - Ngôn ngữ SQL
- Các khái niệm, thành phần cơ bản trong SQL
- Các nhóm lệnh cơ bản trong SQL
- Kiểu dữ liệu trong SQL Server
- Select statement
- Select statement: Cú pháp câu điều kiện (DISTINCT, WHERE, IN, ORDER BY, AND, OR, NOT,...)
- SQL statement with aggregate functions (COUNT, SUM, AVERAGE , MIN, MAX, ..)
- Bài tập thực hành
- Truy vấn sql nâng cao với các hàm báo cáo thống kê
- GROUP BY HAVING
- ROLLUP, CUBE, PIVOT, LAG
- Constraint
- DML statement
- Bài tập thực hành
- Functioin (Hàm)
- If ... else ...
- case ... when ...
- vòng lặp while
- cursor (con trỏ) bảng tạm with cte Bài tập thực hành
- Công cụ turning, debug, tracing
- Tối ưu hóa câu lệnh SQL
- Execution plan (Kế hoạch thực thi)
- Bài tập thực hành
- bán hàng online
- book phòng khách sạn
- đặt vé sự kiện
- quản lý nhân sự...
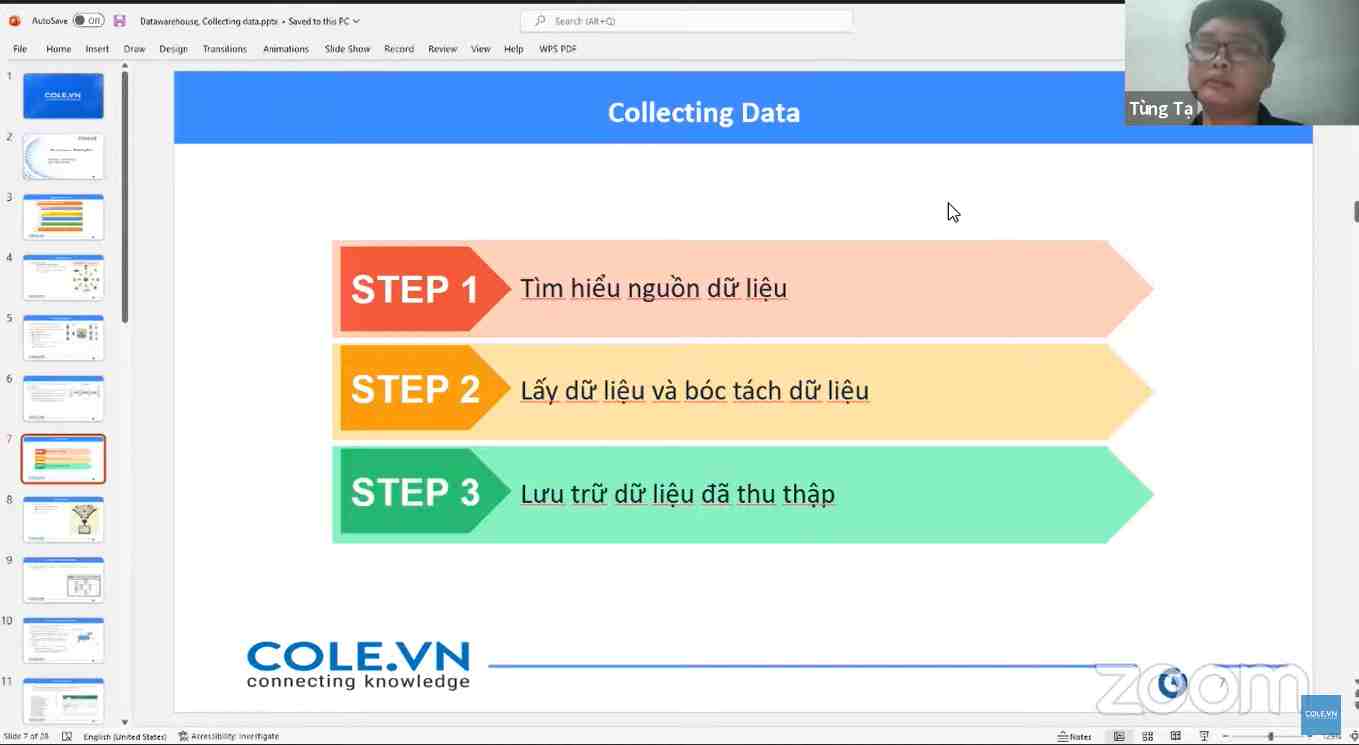
- Tổng quan về ETL
- Transform
- Load
- SSIS
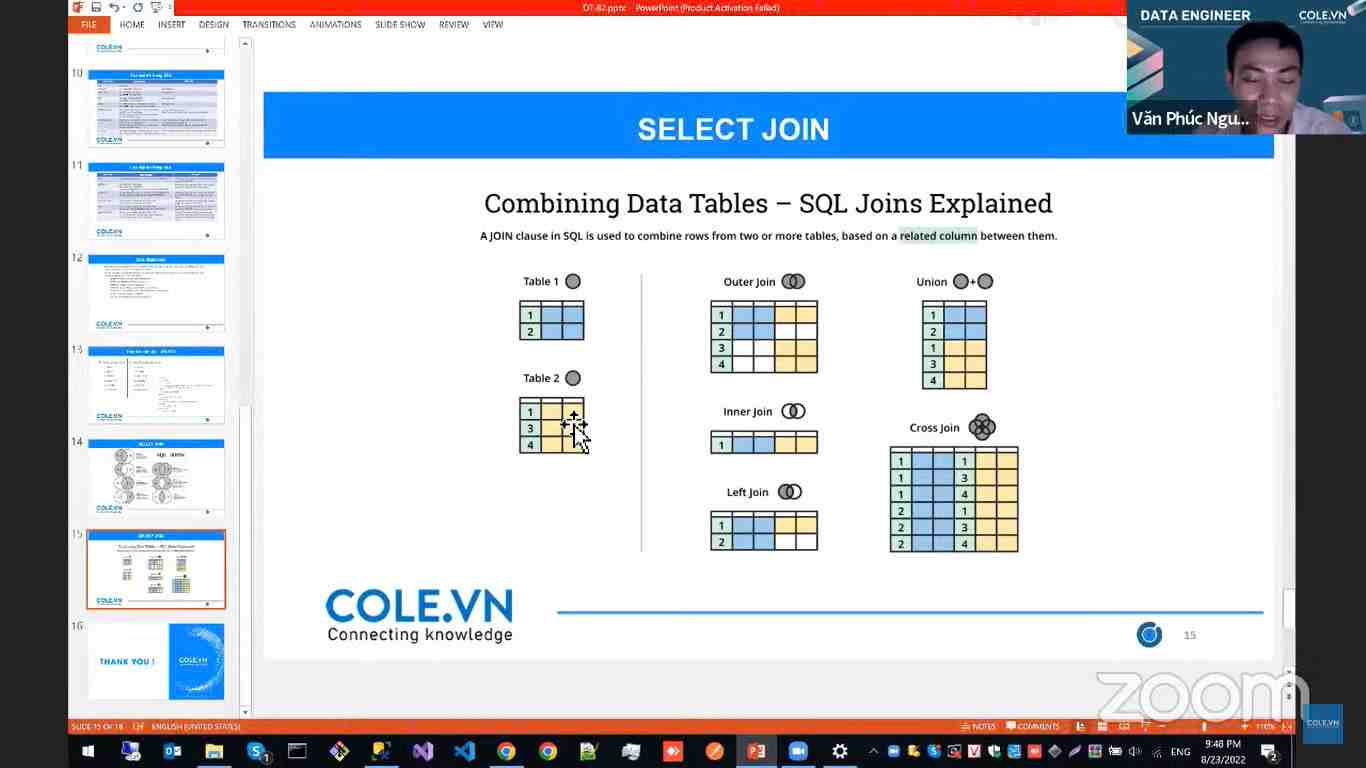
- Tổng quan trực quan hóa dữ liệu
- Xây dưng các biểu đồ
- AWS console
- IAM
- Các dịch vụ dữ liệu của AWS
- Cách tạo RDS và kết nối tới database
- Giám sát trạng thái hoạt động của server
- Backup dữ liệu định kỳ
- Bài tập thực hành
- Sử dụng công cụ aws-cli để upload/download file
- Sử dụng athena để truy vấn dữ liệu trên S3
- Bài tập thực hành
- Một số cú pháp truy vấn cơ bản
- Backup định kỳ
- Bài tập thực hành
- Data Catalogue
- Crawler
- Visual ETL
- Bài tập thực hành
- Các phép biến đổi dữ liệu thông dụng
- Bài tập thực hành
- Xây dựng pipeline để tổng hợp và khai thác dữ liệu từ nhiều nguồn
- Kéo dữ liệu từ nhiều nguồn
- Basic Programming Constructs
- Predefined Functions
- Overview of Collections - list and set
- Overview of Collections - dict and tuple
- Jupyter Notebooks and Loading Data
- Pandas vs Numpy
- Creating DataFrames
- Saving and Serialising
- Inspecting DataFrames
- Introduction and super basic plots
- Pandas vs Matplotlib
- Visualising 1D distributions
- Visualising 2D distributions
- Styling Pandas Table outputs
- Higher dimension visualisations
- Introduction, Labelling and Ordering
- Slicing and Filtering
- Removing and adding data
- Apply, map and vectorised functions
- Introduction and motivation
- Basic grouping syntax
- Intelligent imputation
- Grouping aggregation
- Introduction and basic syntax
- Different types of merging
- Helpful merging functions
- Introduction and basic MultiIndexes
- MultiIndex II - MultiIndex Strikes Back
- Stacking and Unstacking
- Pivoting
- Pivot Margins
- Data Vault 2.0 Modeling
- Getting Started
- File Management
- Directory Management
- File Permission / Access Modes
- Environment
- Printing, Email
- Pipes and Filters
- Processes Management
- Network Communication Utilities
- The vi Editor Tutorial
- What is Shells?
- Using Shell Variables
- Special Variables
- Using Shell Arrays
- Shell Basic Operators
- Shell Decision Making
- Shell Loop Types
- Shell Loop Control
- Shell Substitution
- Big Data Solutions
- Introduction
- Enviornment Setup
- HDFS Overview
- Command Reference
- MapReduce
- Streaming
- Multi-Node Cluster
- Perform a bulk data import on your EMR cluster, targeting your HBase table using the next two files in your dataset with appropriate scripts.
- Develop MapReduce code to process and analyze the downloaded files on your EMR instance.
- Use the Sqoop export command to transfer the output from each MapReduce task back to your RDS instance. Visualize the data by connecting the RDS instance to a dashboarding tool, such as Google Data Studio, Tableau, or PowerBI.
- Spark Basics and the RDD Interface.
- Running Spark on a Cluster.
- CLI (Command Line Interface) 101.
- Start Kafka
- Start a MySQL database
- Start a MySQL command line client
- Start Kafka Connect
- Workflows as code
- Why Airflow?
- Why not Airflow?
- It’s a DAG definition file
- Importing Modules
- Default Arguments
- Instantiate a DAG
- Operators
- Tasks
- Automated Testing in Big Data
- Version Control and Configuration Management
- Python and Pyspark package management
The project involves handling two data types: clickstream data and batch data.
- Clickstream Data: This real-time data, captured in Kafka, is consumed by a streaming framework, which loads it into Hadoop. Once ingested into the stream processing layer, the data is synced to an HDFS directory for further processing.
- Batch Data: This consists of bookings data stored in an RDS instance. This data needs to be ingested periodically into Hadoop for analysis and processing.
Giảng viên

Data Architecture tại Tập đoàn BRG
- 15+ năm kinh nghiệm làm việc thực tế về chuyển đổi số, tham gia phát triển nhiều dự án CNTT lớn. Tham gia đánh giá, tư vấn hỗ trợ trong việc mua sắm phần mềm cho doanh nghiệp.
- Đã có kinh nghiêm làm việc chuyển đổi số trong và ngoài nước (Mỹ và Malaysia) - Tập đoàn BestBuy.Com với vai trò là key chính (kỹ sư dữ liệu).
- Đã chuyển đổi số trong nhiều lĩnh vực từ doanh nghiệp nước ngoài, chính phủ, và doanh nghiệp tư nhân
- Làm việc với nhiều vai trò khác nhau từ nhân viên, thầy giáo, tư vấn, quản trị dự án, lãnh đạo CNTT trong doanh nghiệp, chủ doanh nghiệp, làm các dự án startup.
- Đã làm các dự án phần mềm (chuyển đổi số) cho chính phủ (Chính phủ điện tử Đà Nẵng, Một cửa quốc gia, Chính phủ điện tử cho bộ Y tế, Bộ giao thông vận tải, Văn phòng chính phủ…).
- Đã đào tạo đội làm chính phủ điện tử bên VNPT , đào tạo STEM và có đưa team học sinh Việt Nam đi thi đấu tại Indonesia.
- Hiện tại phụ trách phần mềm, EA (enterprise architecture) của Tập đoàn BRG (Công ty đa ngành sở hữu ngân hàng SeaBank, Golf, Khách sạn, BDS, Dược phẩm……)
- Tốt nghiệp kỹ sư CNTT ngành ngành Toán - Tin Đại học Bách khoa Hà Nội.
- Từng làm giảng viên tại Aptech.

Senior Data Analyst - Business Inteligence tại Corp360
Senior Data Analyst - Business Inteligence tại Corp360

Principal Engineer tại IX - Công ty chuyển đổi số hàng đầu Nhật Bản
- Xây dựng các hệ thống Data Warehouse, Big Data tại tập đoàn Mynavi (công ty tuyển dụng lớn nhất Nhật Bản)
- 5 năm kinh nghiệm làm việc trực tiếp tại Nhật Bản
- 12 năm kinh nghiệm làm chuyển đổi số khách hàng Nhật Bản

Data Architect at Bosch Digital
- 7+ năm kinh nghiệm xây dựng và phát triển Big Data Platform tại ACB Bank và Bosch.
- 2+ năm phát triển và vận hành quy trình tự động hóa với vai trò RPA Engineer tại FPT và Bosch.
- Chứng chỉ:
- Big Data Specialization - Đại học California, San Diego.
- BI Foundations with SQL, ETL and Data Warehousing - IBM.
Project học viên
Feedback học viên

Nguyễn Thùy Linh
Intern Data Engineer tại tập đoàn FPT

Ngô Thái Huy
Fresher Data Engineer tại Viettel

Thái Thùy Trang
Junior Data Engineer tại CMC
Lợi ích chỉ có tại COLE
Giới thiệu việc làm sau khóa học
Học lại free
Cộng đồng chuyển đổi số 1
Câu hỏi thường gặp
Để biết thêm thông tin chi tiết đừng ngần ngại gọi cho chúng tôi.
-
Hotline
-
Email
-
Trang tin chính thức
Hoặc để lại thông tin

COLE - Lựa chọn hàng đầu cho nhân
sự về Digital Skills

5000+
Học viên theo học

30%
Thu nhập học viên tăng lên sau khi học

30+ Khóa học
Hàng đầu về ứng dụng công nghệ

50+
Chuyên gia hàng đầu về chuyển đổi số
300+ Doanh nghiệp hàng đầu lựa chọn Cole để nâng cấp kỹ năng
Hình ảnh lớp học