Khóa Master Class DataOps for Data Platforms: From Pipeline to Production| Bootcamp


Thời lượng
11 buổi

Hình thức đào tạo
Online qua Zoom

Học phí
Liên hệ
Tổng quan
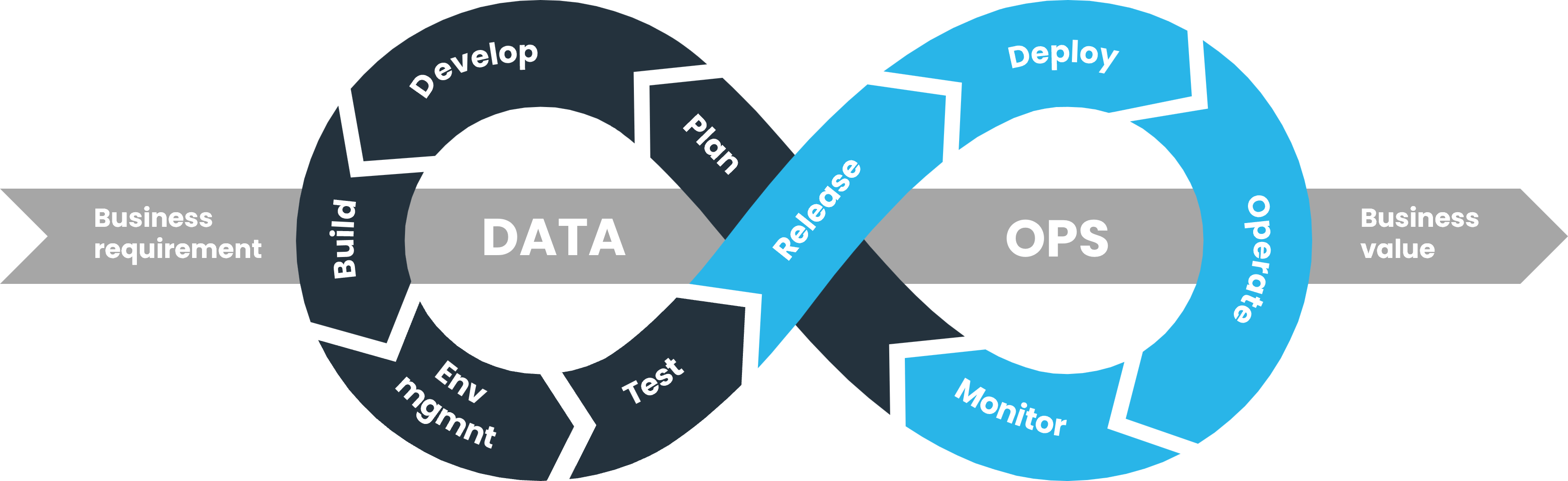
Lợi ích khóa học
Thực hành trên dữ liệu thực tế
Học viên sẽ được thực hành trên các bộ dữ liệu mô phỏng giao dịch thực tế (eCommerce / tài chính), giúp hiểu rõ cách xây dựng và vận hành data pipeline trong môi trường production
Hỗ trợ tài nguyên toàn diện
Được cung cấp đầy đủ slide bài giảng, notebook thực hành, source code toàn bộ pipeline, setup lab
Thời lượng
12 buổi chuyên sâu + Final Production Project.
Đồng hành cùng giảng viên và record
Được hỗ trợ giải đáp trong suốt chương trình, có recording đầy đủ các buổi học để xem lại.
Chứng nhận & Học bổng
Nhận chứng nhận hoàn thành khóa học và cơ hội được hoàn 50% học phí cho Top 3 Final Project xuất sắc nhất.
Lịch học
Thứ 4 & Thứ 6 hàng tuần (20:00 – 22:00) .
Mục tiêu học tập
Đối tượng học tập
Chuẩn đầu ra
Kiến thức & Kỹ năng đạt được:
Kiến thức & Kỹ năng đạt được:
- Thiết kế & vận hành pipeline reliable theo tư duy DataOps.
- Viết pipeline idempotent & reconciliation, an toàn khi chạy lại.
- Vận hành được trên stack DWH (SQL) hoặc Lakehouse (PySpark).
- Áp dụng bảo mật cơ bản: secrets, masking PII, phân quyền.
- Thiết lập CI/CD, monitoring & data quality testing.
- Viết runbook & xử lý sự cố cơ bản.
Sau khóa học, học viên sẽ:
Sau khóa học, học viên sẽ:
- Hiểu tư duy DataOps & vì sao reliability quan trọng (idempotency, reconciliation)
- Viết pipeline an toàn với Airflow & triển khai ổn định
- Vận hành reliable trên 2 stack: SQL Data Warehouse & PySpark Lakehouse
- Biết tối ưu hiệu năng & chi phí ở mức cơ bản
- Áp dụng security cơ bản: secrets, masking PII, phân quyền
- Thiết lập CI/CD, monitoring, data quality & cảnh báo cho pipeline
- Dùng lineage để truy vết sự cố, viết runbook & nắm khái niệm backup/DR
- Hoàn thiện 1 project DataOps để đưa vào CV/Portfolio
Lộ trình học tập
• Vì sao reliability quan trọng - nhất là với dữ liệu tài chính / giao dịch
• Nguyên lý cốt lõi: idempotency, reproducibility, reconciliation.
• Thế nào là pipeline chuẩn trên Production.
• Tổng quan tech stack & lộ trình: Python, SQL, Spark, Airflow, Prometheus/Grafana.
• Các component: Scheduler, Executor, Webserver, Metadata DB, Worker
• Các loại Executor: Local / Celery / Kubernetes - khác nhau ra sao
• Các hướng triển khai: local Docker, Docker Compose, trên Kubernetes (Helm)
• Giới thiệu khái niệm HA & GitOps cho Airflow
• Idempotency & atomicity - vì sao cực kỳ quan trọng
• Scheduling: cron, schedule interval, catchup; backfill an toàn
• Retry, timeout, SLA, alert; dependency giữa Task & giữa DAG
• XCom, Pool, Connection, Variable, Sensor
• Transaction & chạy lại không nhân đôi dữ liệu
• Reconciliation - đối soát số liệu để đảm bảo đúng/đủ
• Quản lý dependency giữa các bước SQL
• Triển khai stack Lakehouse trong DataOps
• PySpark pipeline reliable: atomic & idempotent writes, partition overwrite an toàn
• Table format (Delta/Iceberg): ACID & time travel giúp pipeline an toàn
• Case study: migrate DWH → Data Lake an toàn, minimal-downtime
• Đọc query plan (DWH) & Spark UI (Lakehouse) tìm bottleneck
• Bottleneck phổ biến: data skew, small-files, shuffle
• Partitioning, caching, broadcast join cơ bản
• Tối ưu chi phí cloud
• Xử lý PII: masking, encryption, anonymization
• Phân quyền truy cập dữ liệu (least privilege)
• Governance cho dữ liệu regulated (vd: tài chính, ngân hàng)
• Audit logging cơ bản
- Test cho pipeline: unit test (Python/SQL/Spark) & data test
- CI: tự động lint + test khi có thay đổi code
- CD: tự động deploy pipeline lên môi trường (local / Docker)
- Khái niệm GitOps & rollback (giới thiệu)
• Metric cơ bản & dashboard với Prometheus + Grafana
• Alerting đúng cách - tránh alert fatigue
• Data quality testing với Great Expectations (schema, null, duplicate, business rule)
• Theo dõi data freshness & reconciliation tự động
• Dùng metadata & lineage để truy vết tác động & nguồn gốc lỗi
• Runbook - kịch bản xử lý sự cố lặp lại
• Backup & Disaster Recovery: khái niệm RTO/RPO
• Case study: trợ lý DataOps tự động điều tra sự cố & gợi ý runbook (LLM agent)
Hướng dẫn hoàn thành Final Project:
• Giới thiệu đề bài final project & bối cảnh nghiệp vụ
• Yêu cầu đầu ra bắt buộc & tiêu chí đánh giá
• Gợi ý kiến trúc & lựa chọn stack (DWH vs Lakehouse)
• Trình bày quyết định thiết kế: reliability, security, monitoring
• Review chéo & feedback từ mentor
• Tổng kết & career roadmap: DataOps / Platform Engineer
- Xây dựng pipeline đưa dữ liệu giao dịch (eCommerce/POS hoặc tài chính) thành các bảng phân tích phục vụ báo cáo.
- Pipeline phải idempotent, an toàn khi chạy lại / backfill, có reconciliation đối soát số liệu.
- Có kiểm thử chất lượng dữ liệu, giám sát & cảnh báo khi sự cố.
- Dữ liệu nhạy cảm (PII) được che/giấu & phân quyền.
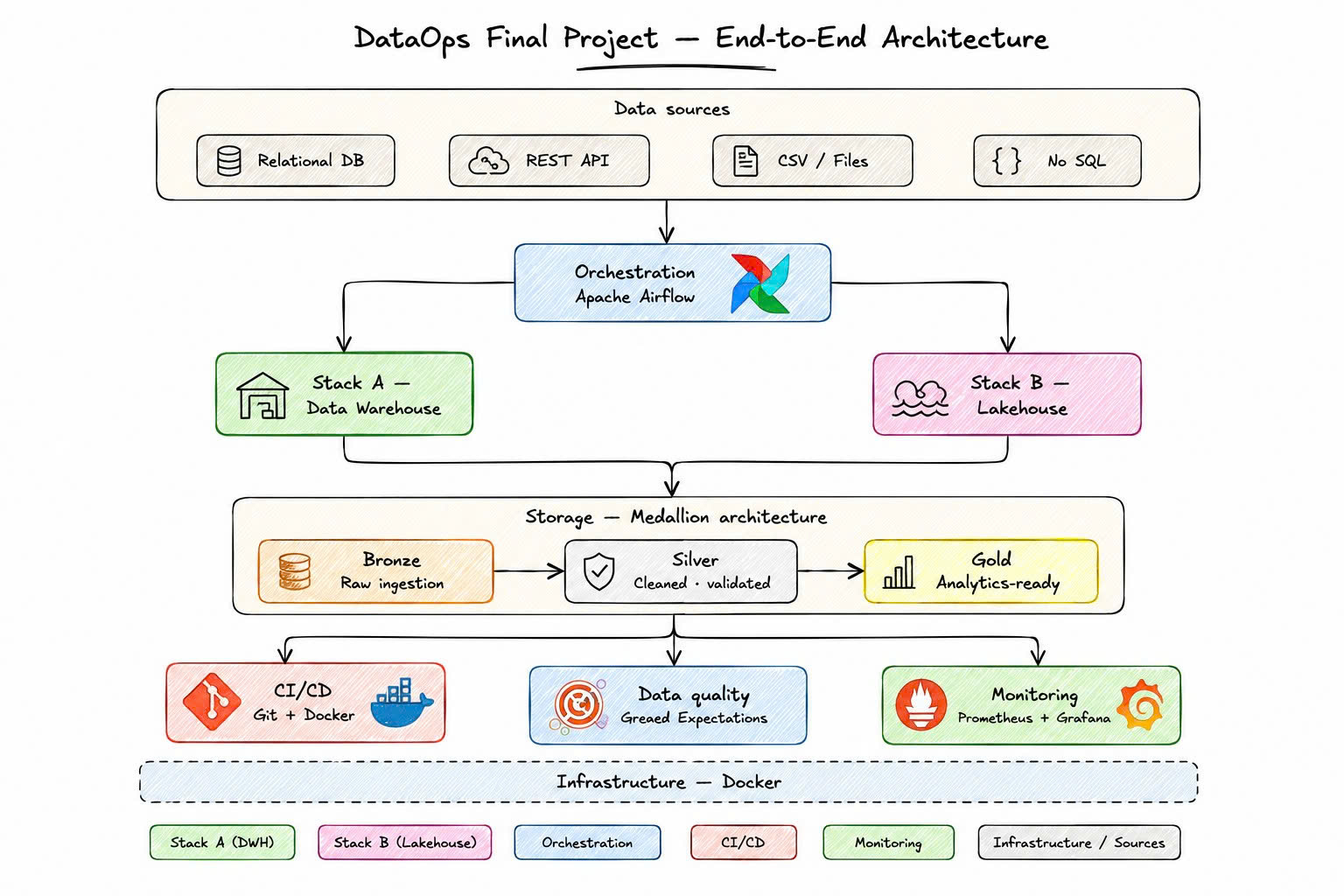
Kiến trúc tổng quan (chọn 1 trong 2 stack)
- Stack DWH: SQL trên Data Warehouse (Postgres/BigQuery...), hoặc
- Stack Lakehouse: PySpark + table format (Delta/Iceberg) trên object storage.
- Điều phối bằng Apache Airflow.
- CI/CD chạy trên local / Docker.
- Monitoring bằng Prometheus + Grafana; kiểm thử dữ liệu bằng Great Expectations.
- Có runbook xử lý sự cố cơ bản.
- Triển khai bằng Docker Compose.
Giảng viên

Nguyễn Hoàng Quốc Anh - Senior Data Engineer / Senior DataOps tại Techcombank
- Kinh nghiệm sâu về Data / Ops Engineer (Banking & E-Commerce)
- Xây dựng & phát triển data pipeline ở quy mô lớn (batch & streaming)
- Thiết kế, vận hành data platform trên Kubernetes (Docker, Airflow, Terraform)
- Chuyên sâu streaming pipeline xử lý hàng triệu event/ngày, latency thấp
- Tối ưu hạ tầng & pipeline, tiết kiệm đáng kể chi phí vận hành
- Vững về data quality, reconciliation & governance cho dữ liệu tài chính / e-commerce.
Lợi ích chỉ có tại COLE
Giới thiệu việc làm sau khóa học
Học lại free
Cộng đồng chuyển đổi số 1
Câu hỏi thường gặp
Để biết thêm thông tin chi tiết đừng ngần ngại gọi cho chúng tôi.
-
Hotline
-
Email
-
Trang tin chính thức
Hoặc để lại thông tin

COLE - Lựa chọn hàng đầu cho nhân
sự về Digital Skills

5000+
Học viên theo học

30%
Thu nhập học viên tăng lên sau khi học

30+ Khóa học
Hàng đầu về ứng dụng công nghệ

50+
Chuyên gia hàng đầu về chuyển đổi số
300+ Doanh nghiệp hàng đầu lựa chọn Cole để nâng cấp kỹ năng