Sự bùng nổ của các Mô hình ngôn ngữ lớn (LLM) như ChatGPT đã thay đổi hoàn toàn cách chúng ta tìm kiếm thông tin. Tuy nhiên, LLM vẫn tồn tại 3 nhược điểm cốt tử: không nắm được dữ liệu nội bộ (private data), kiến thức bị giới hạn bởi thời gian huấn luyện và rất dễ bị 'ảo giác' (hallucination) – tự bịa ra câu trả lời khi không biết.
Để giải quyết bài toán này, kiến trúc RAG (Retrieval-Augmented Generation) ra đời. Hôm nay, thông qua bài phân tích Project RAG Chatbot của bạn Tuấn Anh – Sinh viên năm 3 chuyên ngành Khoa học Máy tính Đại học Bách Khoa Hà Nội, chúng ta sẽ cùng bóc tách cách thức hoạt động và luồng xây dựng một hệ thống hỏi đáp tài liệu PDF thông minh, linh hoạt.
Mục Lục
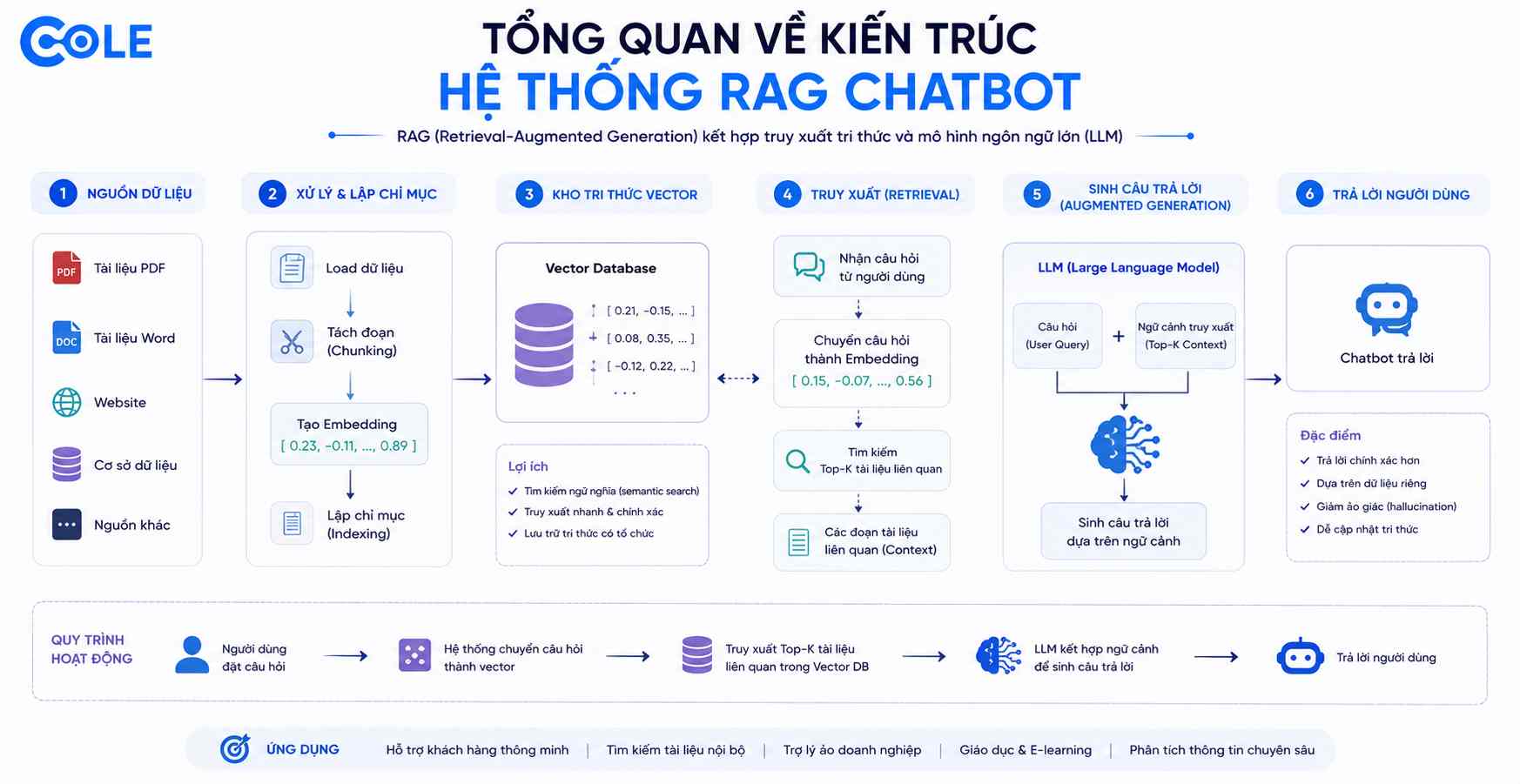
1. Tổng Quan Về Kiến Trúc Hệ Thống RAG Chatbot
Dự án RAG Chatbot này được thiết kế để giải quyết bài toán: Làm thế nào để AI đọc một file PDF chứa kiến thức chuyên ngành (ví dụ: tài liệu khoa học công nghệ, quy chế công ty) và trả lời câu hỏi dựa CHÍNH XÁC trên tài liệu đó?
Hệ thống được thiết kế module hóa mạnh mẽ, chia thành các luồng xử lý riêng biệt:
App Config: Trung tâm quản lý cấu hình (định cỡ chunk size, độ chồng lấp overlap, thư mục lưu trữ vector).
Document Indexer: "Trái tim" của hệ thống, nhận nhiệm vụ đọc file PDF, băm nhỏ dữ liệu và nhúng (embedding).
Vector Database (ChromaDB): Lưu trữ dữ liệu sau khi đã được vector hóa để tối ưu hóa truy xuất.
Retriever: Trình tìm kiếm ngữ nghĩa, so sánh câu hỏi người dùng với database để trích xuất đoạn văn bản liên quan.
LLM Client: Giao tiếp với API của các mô hình ngôn ngữ như OpenAI (ChatGPT) hoặc mô hình mã nguồn mở chạy local (Ollama).
Streamlit UI: Giao diện tương tác người dùng thân thiện.
2. Phân Tích Luồng Hoạt Động Của RAG Chatbot
Quá trình hoạt động của hệ thống được thực hiện qua hai giai đoạn chính: Xử lý tài liệu đầu vào và Xử lý truy vấn của người dùng.
Giai đoạn 1: Chuẩn bị tri thức (Document Indexing)
Tải tài liệu (Loading): Hệ thống sử dụng
PyPDFLoaderđể đọc nội dung file PDF do người dùng tải lên, trích xuất cả nội dung chữ (context) lẫn siêu dữ liệu (metadata như số trang).Chia nhỏ văn bản (Text Splitting): Đây là bước cực kỳ quan trọng. Văn bản dài sẽ được cắt thành các đoạn nhỏ (chunk) với kích thước và độ chồng lấp (chunk overlap) nhất định bằng Text Splitter.
- Lý do: Các mô hình embedding hoạt động hiệu quả nhất trên các đoạn văn bản ngắn mang ý nghĩa rõ ràng. Nếu để đoạn văn quá dài (ví dụ 3000 ký tự), vector sinh ra sẽ bị "trung bình hóa" nhiều chủ đề, làm giảm độ chính xác khi tìm kiếm. Việc có overlap (khoảng lùi) giúp các câu văn bị cắt ngang không mất đi ngữ nghĩa liên kết.
Nhúng dữ liệu (Embedding): Mỗi đoạn chunk sẽ được chuyển đổi thành một chuỗi số học (vector) thông qua các mô hình embedding (như OpenAI Embedding).
Lưu trữ (Storing): Các vector cùng với nội dung text và metadata được lưu vào Vector Database (ở dự án này là ChromaDB).
Giai đoạn 2: Xử lý truy vấn (Query & Retrieval)
Nhập câu hỏi: Người dùng đặt câu hỏi thông qua giao diện Streamlit.
So sánh Vector (Semantic Search): Câu hỏi cũng được nhúng thành vector bằng mô hình tương tự. Cỗ máy tìm kiếm (Retriever) sẽ dùng phép tính toán học (như cosine similarity) để đo góc giữa vector câu hỏi và các vector trong ChromaDB. Góc càng nhỏ, nội dung càng liên quan. Từ đó lấy ra Top K đoạn văn bản gần nhất.
Đưa vào LLM (RAG Chain): Đoạn văn bản liên quan vừa tìm được sẽ được "nhồi" vào một Prompt hệ thống cùng với câu hỏi của người dùng. Prompt này được thiết kế kỹ thuật (Prompt Engineering) để yêu cầu AI chỉ trả lời dựa trên ngữ cảnh cung cấp. Nếu không tìm thấy thông tin, AI phải thành thật báo "Không biết" thay vì bịa chuyện.
3. Điểm Nhấn Kỹ Thuật Trong Project RAG
Dự án RAG Chatbot này sở hữu một số điểm tối ưu đáng chú ý về mặt kỹ thuật:
Linh hoạt cấu hình LLM: Hệ thống không bị khóa chết vào một API duy nhất. Người dùng có thể dễ dàng chuyển đổi qua lại giữa OpenAI (tính phí, cloud) và Ollama (miễn phí, chạy local).
Điều chỉnh tham số Temperature: Nhiệt độ (temperature) được điều chỉnh linh hoạt ảnh hưởng đến độ ngẫu nhiên của hàm Softmax ở cuối mạng nơ-ron. Cấu hình mặc định là
0.7giúp chatbot không bị "khô khan", nhưng vẫn không quá bay bổng dẫn đến sai lệch sự thật.Quản lý lịch sử hội thoại (History-Aware Retriever): Chatbot được thiết kế để nhớ lịch sử đoạn chat. Khi người dùng dùng các đại từ nhân xưng hoặc hỏi những câu tiếp nối, hệ thống sẽ nhìn lại lịch sử để suy luận đúng ngữ cảnh.
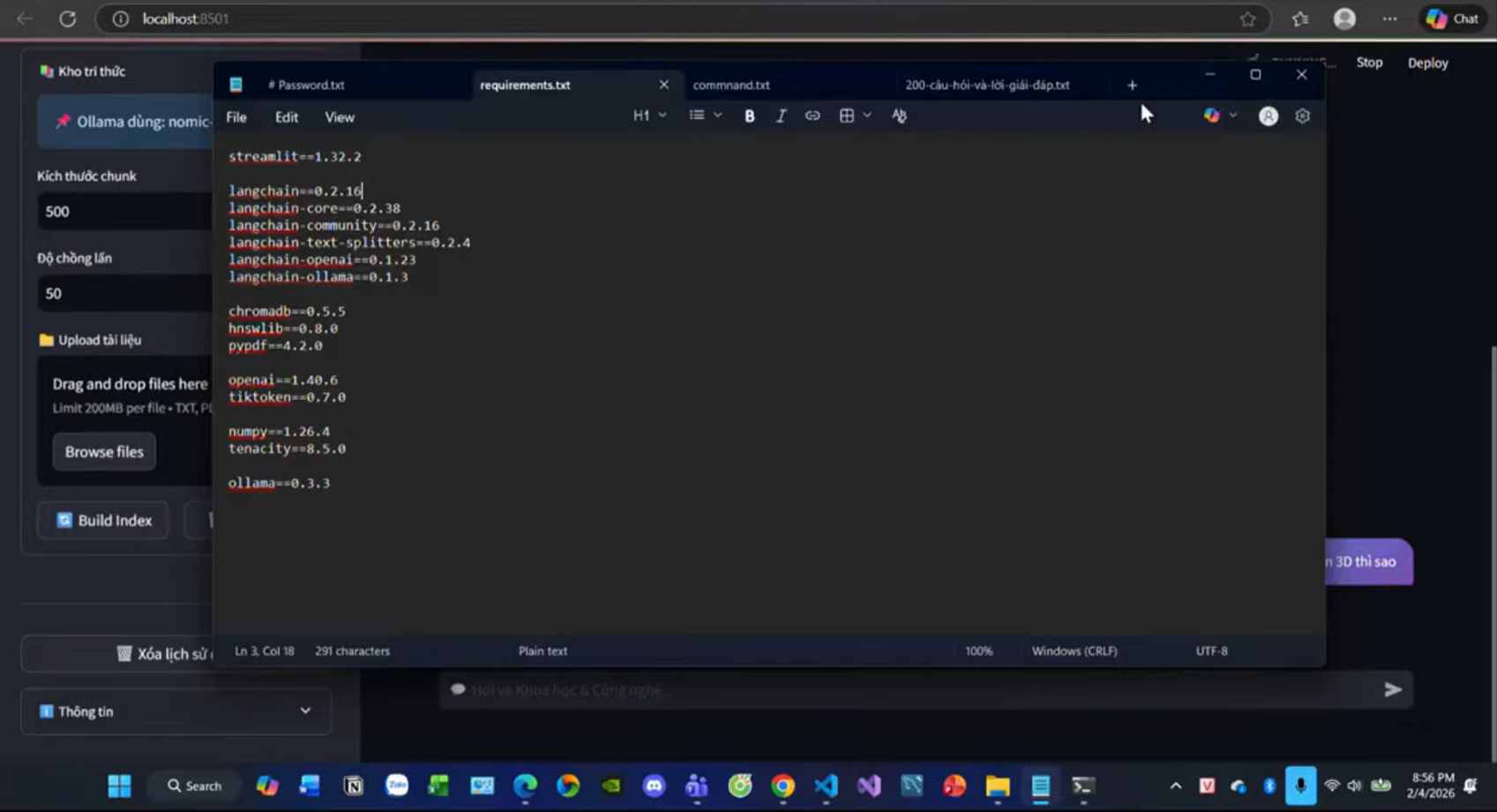
Xử lý lỗi xung đột phiên bản (Dependency Hell): Quá trình làm việc với LangChain thường gặp khó khăn do thư viện cập nhật liên tục. Tác giả đã xử lý triệt để bằng cách đóng gói các phiên bản thư viện cố định tương thích với Python 3.11/3.12 trong file
requirements.txt.
4. Bài Học Rút Ra Về Vector Database & Embedding
Một lỗi kinh điển nhưng rất dễ mắc phải khi xây dựng RAG đã được Mentor của Cole.vn chỉ ra trong buổi bảo vệ: Tuyệt đối không lưu vector từ nhiều mô hình embedding khác nhau vào chung một collection trong Vector DB.
Mô hình embedding của OpenAI sinh ra vector có chiều (dimension) là 1536, trong khi các mô hình khác (như Nomic của Ollama) có thể có cấu trúc chiều khác biệt. Việc nhồi chung chúng vào một không gian dữ liệu sẽ khiến các phép tính khoảng cách (cosine similarity) bị nhiễu loạn, dẫn đến kết quả tìm kiếm sai lệch hoàn toàn. Nếu muốn dùng song song nhiều mô hình, bắt buộc phải tạo các Collection lưu trữ riêng biệt.
Tổng Kết
Hệ thống RAG Chatbot là minh chứng rõ rệt cho việc ứng dụng LLM vào môi trường doanh nghiệp và học thuật, biến AI thành những chuyên gia đọc tài liệu cần mẫn và chính xác. Với một lộ trình học AI Engineer chuẩn sẽ là một hướng đi vô cùng hứa hẹn mà bất kỳ Data Engineer hay AI Developer nào cũng cần nắm vững trong kỷ nguyên AI.
Hy vọng bài viết này đã mang đến cho bạn góc nhìn rõ ràng hơn về kiến trúc RAG. Theo dõi Cole.vn để tiếp tục cập nhật những kiến thức và dự án thực chiến mảng Data và AI mới nhất nhé!
------
* Tìm hiểu thêm:
Khóa học AI Engineer thực chiến